卷四:Pipeline 编排
阅读时长:35-50 分钟 目标:理解场景任务结构,学会修改现有场景任务,并基于内置能力创建新的场景任务 前提:已完成 卷二:场景配置 和 卷三:VLM / DINO 指南,熟悉视频接入、服务分配、实时展示和告警记录 无需额外环境:本篇教程只使用系统内置能力,不涉及 Docker 和模型转换
前三篇中,您已经学会了两件事:
- 使用系统内置的 CV 算法配置常见检测场景
- 使用 VLM / DINO 定义新的检测规则
但到这一步,您仍然主要是在“使用现成能力”。
本篇教程的目标,是让您进入下一层:理解这些能力是如何被组织起来的,并学会自己编排它们。
本篇教程分三步推进:
- 第一章:看懂现有场景任务的内部结构
- 第二章:修改现有场景任务
- 第三章:从零创建新的业务场景任务
说明
本篇教程先讲“怎么组织能力”。 下一篇教程 CosmoEdge 第三方模型移植 教程再讲怎么引入新的第三方模型能力”。
本篇教程学习路径
看懂现有场景任务
↓
在现有的场景任务上做小修改
↓
参照现有结构,从零搭建新的场景任务学完本篇教程后,您将具备:
- 看懂场景任务在做什么
- 判断一个节点应该放在什么位置
- 独立完成常见的节点增删、连线和参数调整
- 基于系统内置能力搭建新的业务逻辑
第一章:理解 场景任务的算法编排
在 CosmoEdge 场景配置指南 教程中,您主要是在“服务分配”页面选择算法、画区域、调参数。这些操作背后,其实都是场景任务下的算法任务在工作。
每个场景任务可以理解为一条“处理链”:
输入 → 推理 → 逻辑处理 → 输出本章不做修改,只看结构。
1.1 打开“未戴安全帽” 场景任务
- 进入场景任务
- 找到 未戴安全帽
- 点击 算法编排
进入后,您会看到一条完整的节点链。
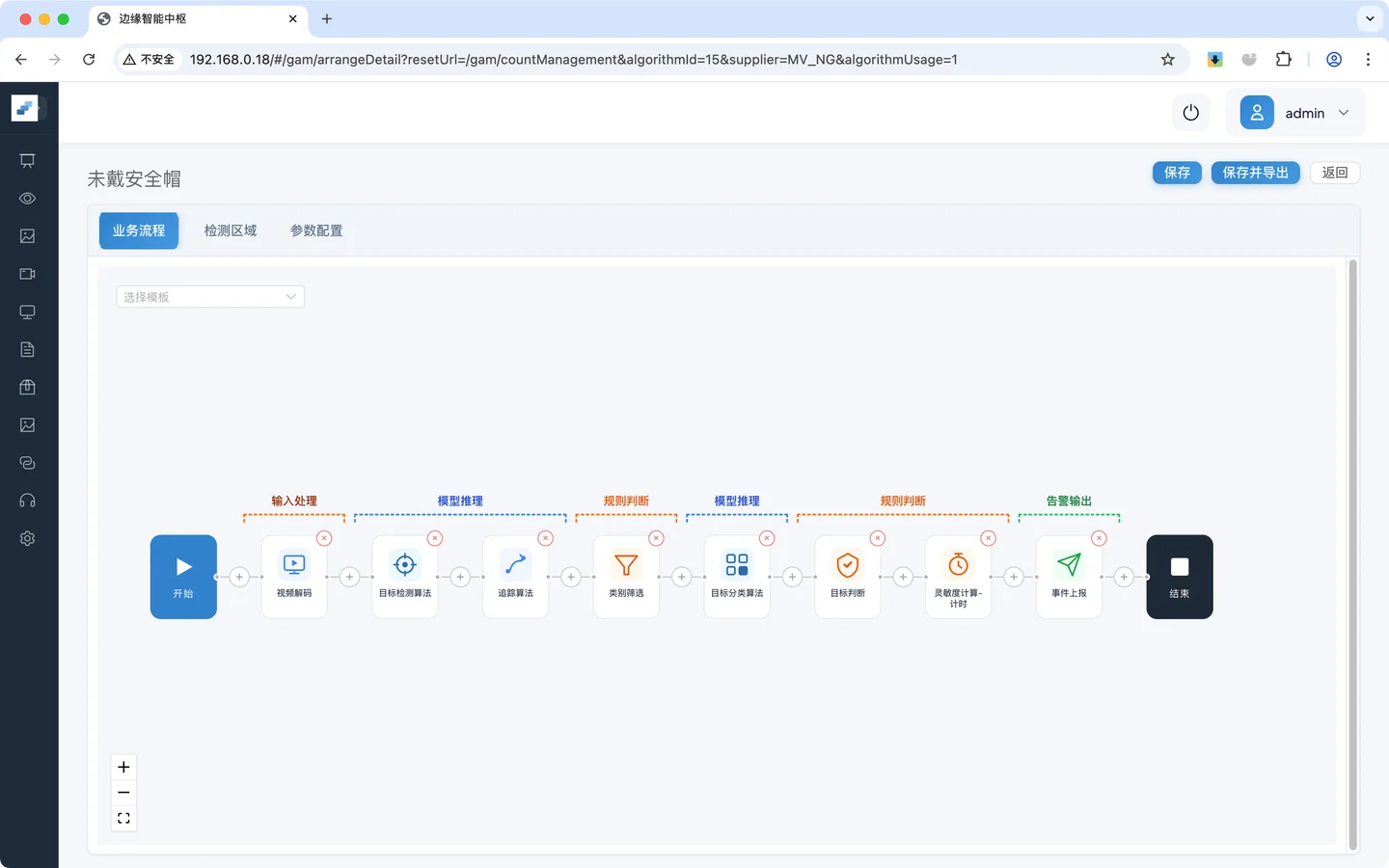
这就是 CosmoEdge 场景配置指南 教程中“未戴安全帽”的内部结构,其业务流程就是根据这里的节点顺序执行。
1.2 认识常见节点类型
输入类节点
| 节点 | 作用 | 备注 |
|---|---|---|
| 视频解码 | 将视频流解码为逐帧图像 | 几乎所有 场景任务的起点 |
推理类节点
| 节点 | 作用 | 备注 |
|---|---|---|
| 目标检测 | 在画面中定位目标 | 例如行人检测、安全帽检测 |
| 目标分类 | 对已检测目标做二次分类 | 例如判断是否戴安全帽 |
| 追踪算法 | 给目标分配稳定 ID | 让同一对象跨帧保持身份 |
| 语言视觉大模型 | 对图像进行状态判断 | 例如“门是开着还是关着” |
| 检测视觉大模型 | 根据文本提示检测目标 | 例如“垃圾桶”“消防柜”等 |
逻辑类节点
| 节点 | 作用 | 备注 |
|---|---|---|
| 类别筛选 | 只保留指定类别 | 去掉不关心的结果 |
| 目标尺寸过滤 | 过滤过小或过大的目标 | 排除远处小目标等干扰 |
| 区域判定 | 判断目标是否进入指定区域 | 对应第二篇教程画的检测区 |
| 越线判定 | 判断目标是否穿过指定线段 | 常用于客流统计 |
| 灵敏度计算 | 多帧累积后再触发告警 | 降低单帧误报 |
输出类节点
| 节点 | 作用 | 备注 |
|---|---|---|
| 事件上报 | 生成告警事件 | 在告警记录中可看到 |
建议
不需要死记所有节点。 更高效的方式是:先找一条最接近的内置 场景任务,再在它的基础上改。
1.3 数据如何在节点之间流转
观察“未戴安全帽” 场景任务,数据大致按下面的顺序流动:
视频解码
↓ 输出:逐帧图像
目标检测(行人检测)
↓ 输出:检测框 + 类别 + 置信度
目标追踪
↓ 输出:检测框 + 类别 + 置信度 + 跟踪序列
类别过滤
↓ 输出:只保留目标类别
目标分类(安全帽分类)
↓ 输出:每个行人的安全帽状态
灵敏度计算
↓ 输出:连续命中后才触发告警
事件上报
↓ 输出:结构化告警事件
视频可视化叠加
↓ 输出:实时画面上的框、标签和提示理解这个流转逻辑后,您就能理解大多数场景任务:
- 每个节点都消费上一个节点的输出
- 每个节点都只做一件事
- 节点顺序会直接影响最终结果
1.4 判断节点顺序的基本原则
在编排时,优先遵守这几个原则:
- 尽早过滤无用结果。 例如太小的目标,应尽量在进入分类或复杂逻辑前就过滤掉。
- 先产生目标,再谈规则。 区域、越线、灵敏度这些逻辑,前提都是上游已经有检测结果。
- 想要在实时画面里“看见效果”,通常需要 视频可视化 叠加节点。 只做事件上报而不做 视频可视化,系统可能会有告警记录,但画面上看不到框。
第二章:修改现有场景任务
在我们已经分享过的“未戴安全帽” 场景任务上做一个实用改动。
场景说明
在 **CosmoEdge 场景配置指南 **的未戴安全帽检测里,远处很小的行人有时也会被检测到。但这些目标像素太少,后面的分类结果往往不够稳定,容易产生误报。解决方法是:在 场景任务中增加一个 目标尺寸过滤 能力,让系统自动忽略过小目标。
2.1 添加类别筛选节点
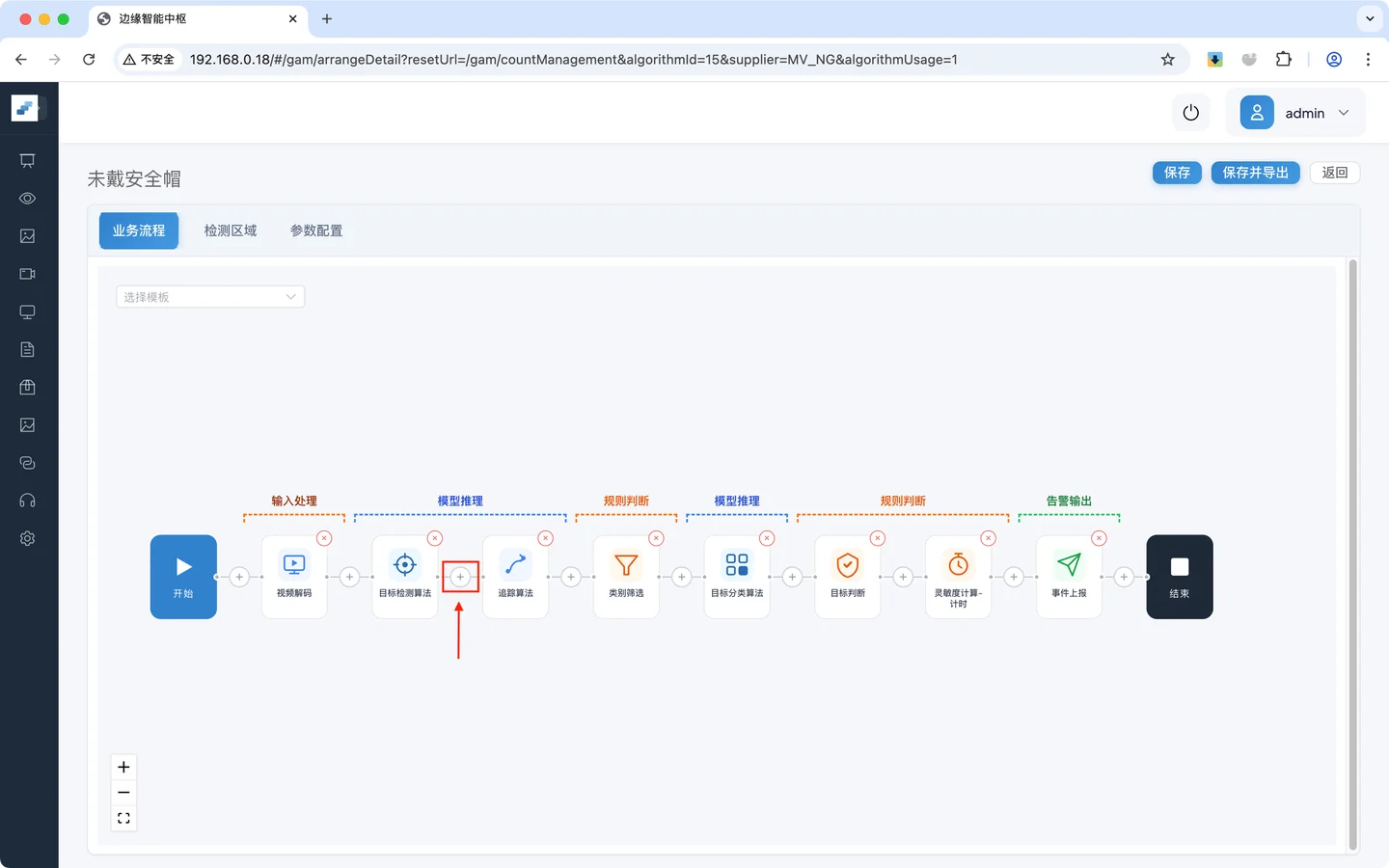
在 **1.1小节 **的步骤继续操作,在 目标检测 和 目标追踪 之间添加一个尺寸过滤
- 点击 目标检测 和 目标追踪 之间的添加按钮
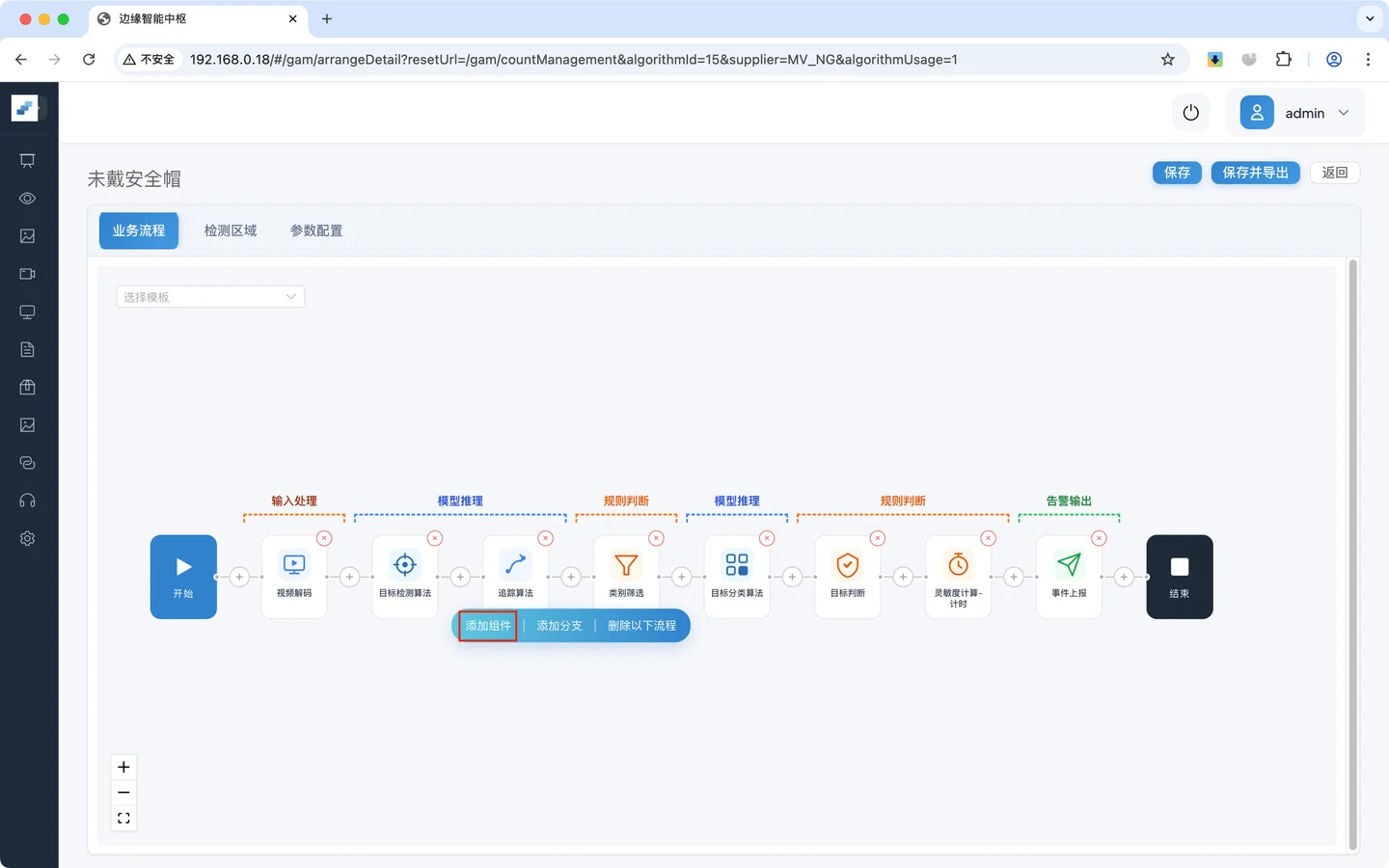
- 点击 添加组件
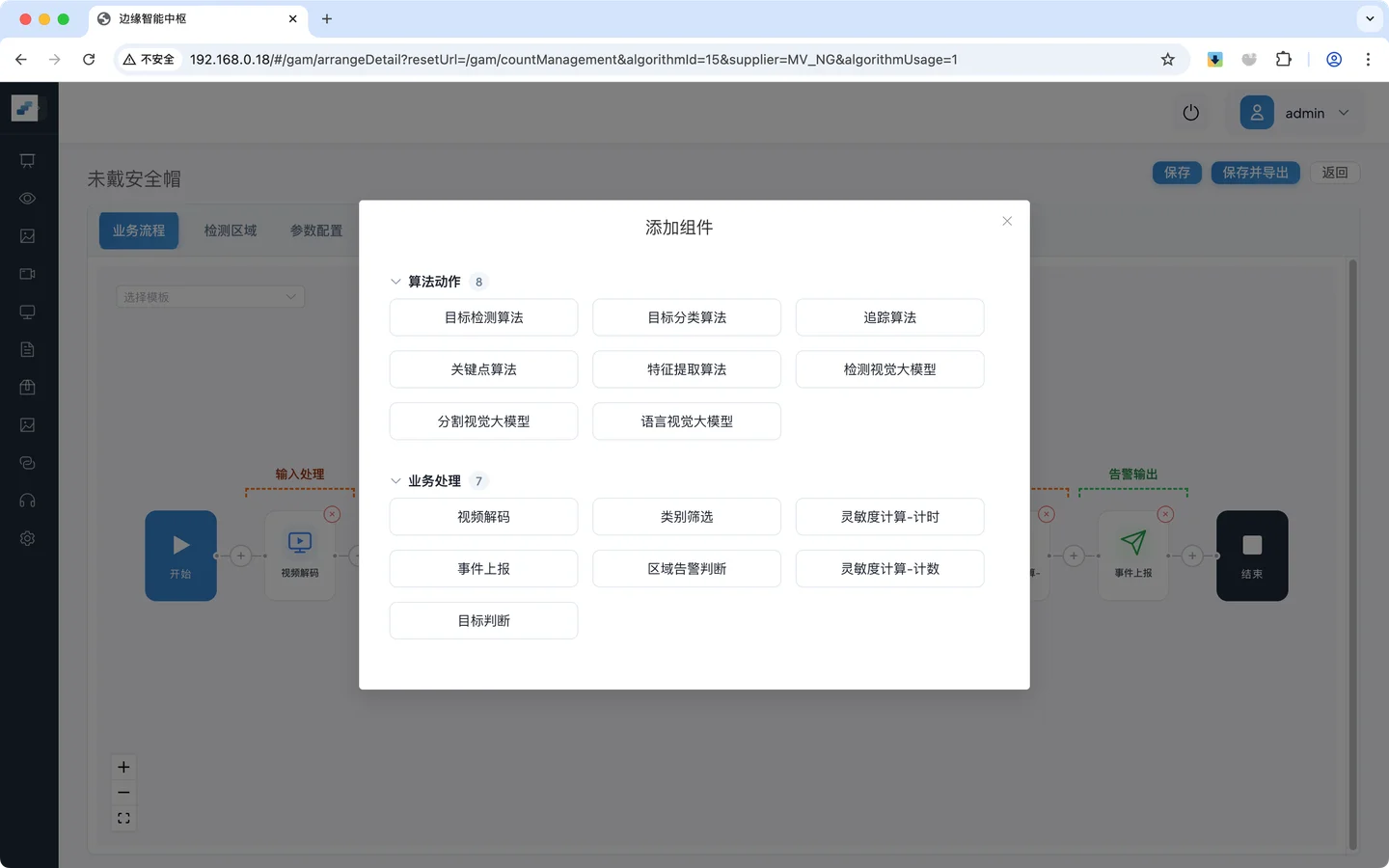
组件包括 算法动作 和 业务处理 两大类:
- 算法动作:模型能力相关的组件,如目标检测、特征提取
- 业务处理:编排流程相关的组件,如视频解码、事件上报
- 选择 **类别筛选 **组件
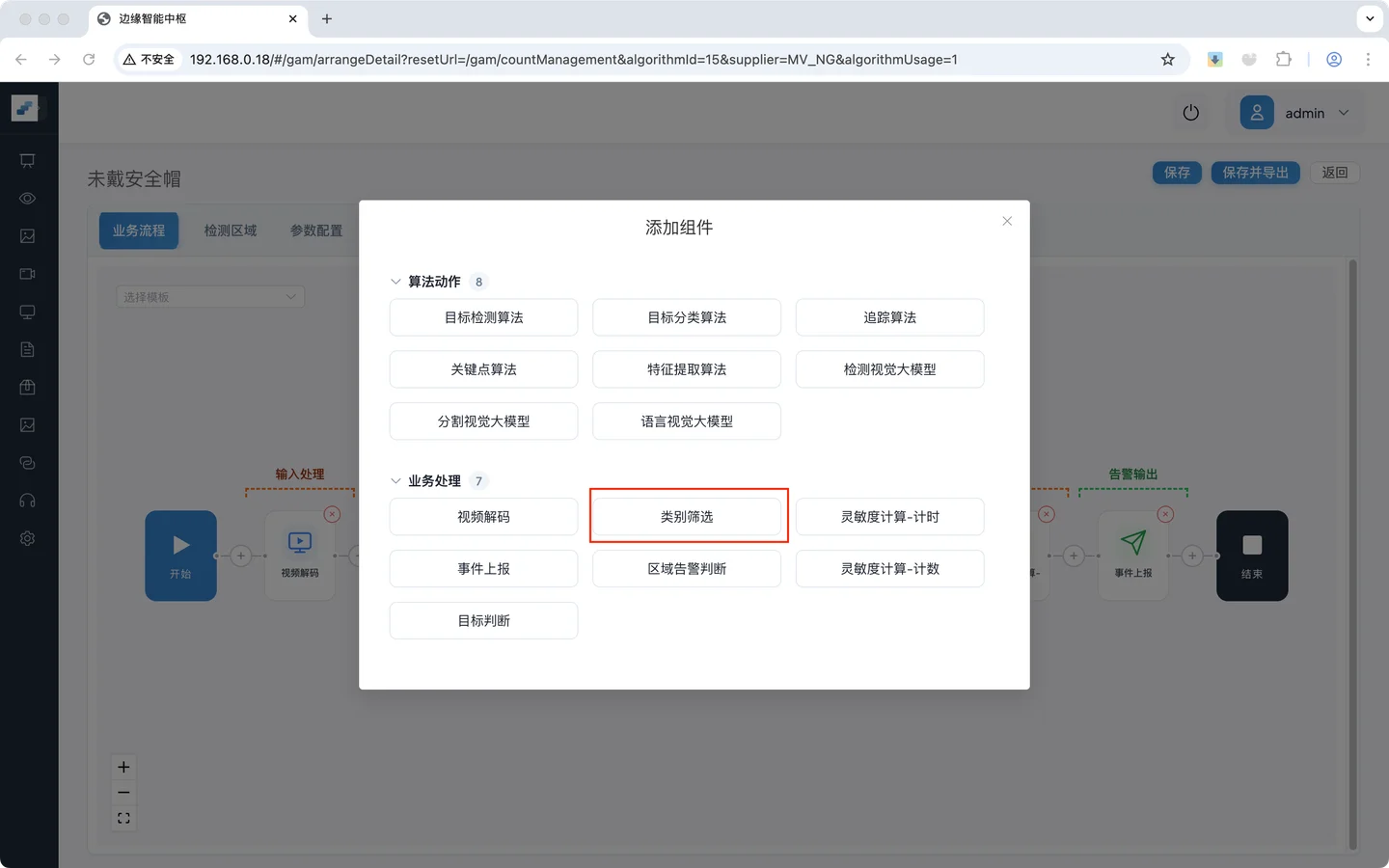
类别筛选组件插入预期位置
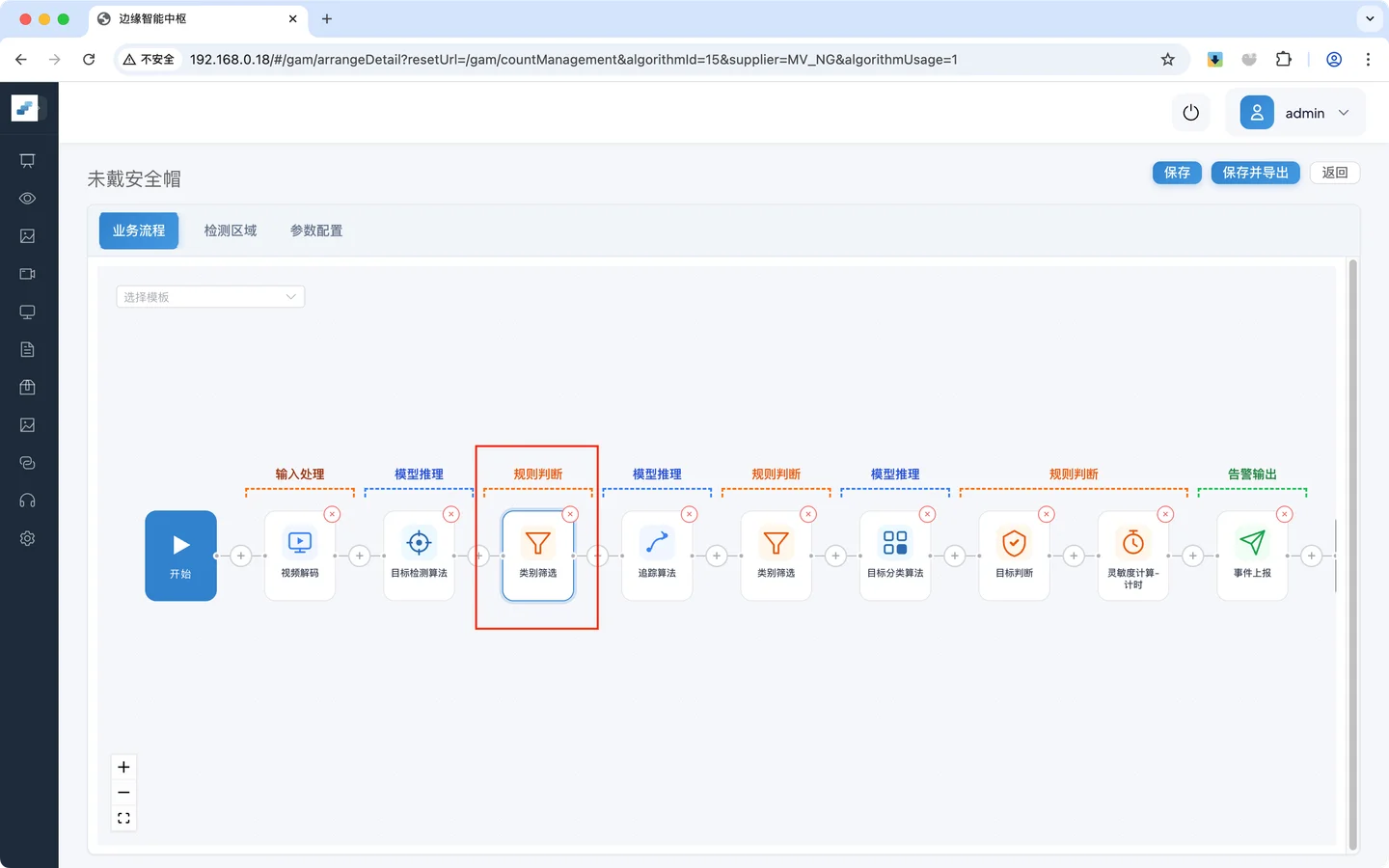
为什么放在这里
尺寸过滤的目的,是尽量早地去掉无效目标。 如果等进入追踪、分类甚至后续规则之后再过滤,既浪费算力,也会增加误报
- 业务逻辑配置
点击 类别筛选 组件,弹出配置项
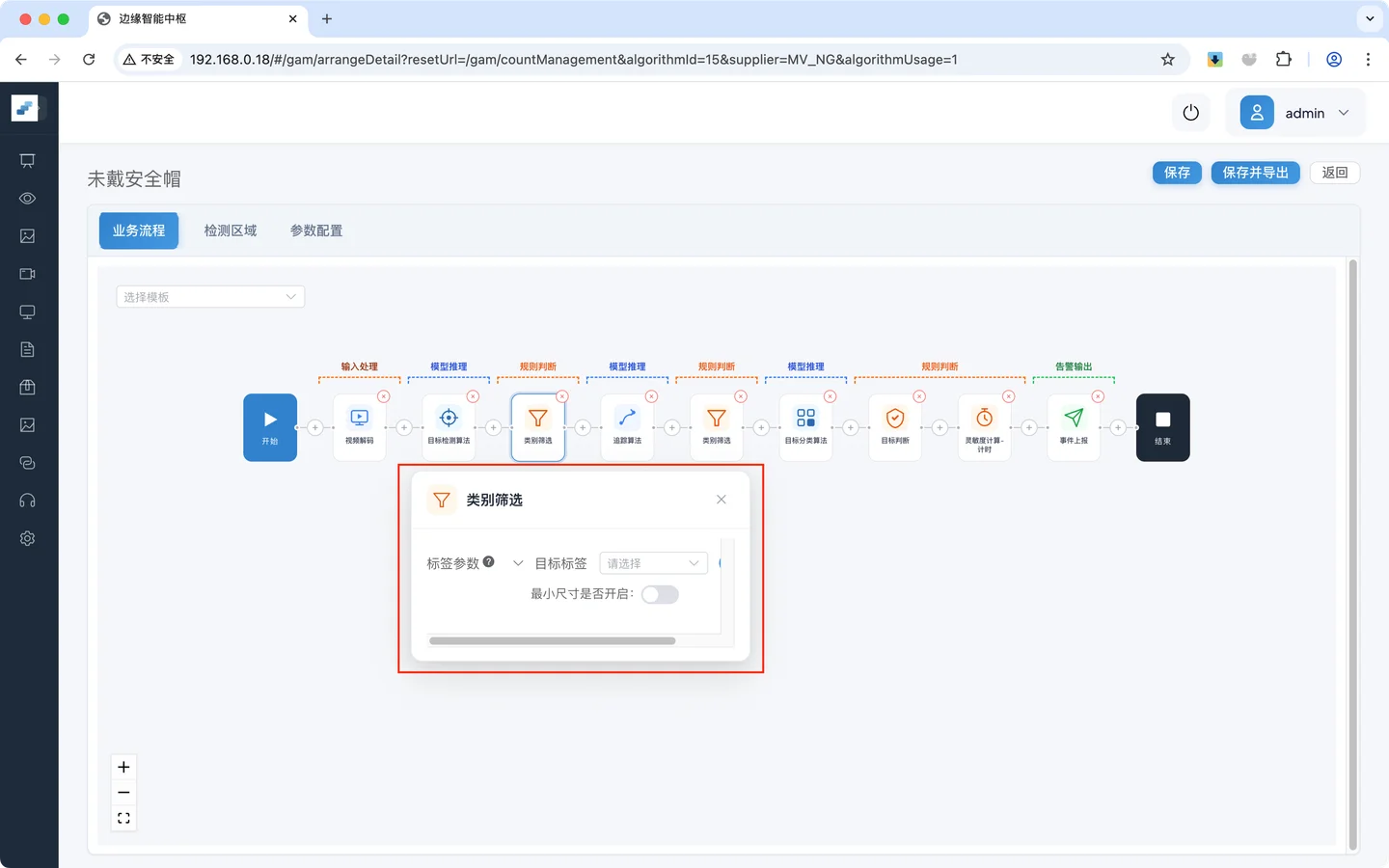
类别筛选 组件的配置项包括:
- 目标标签:筛选出保留的标签
- 最小尺寸是否开启:开启最小尺寸过滤的开关
配置目标标签为 行人,即保留行人这个标签,其他标签丢弃,在后面的流程中只有该标签的预测结果可以使用
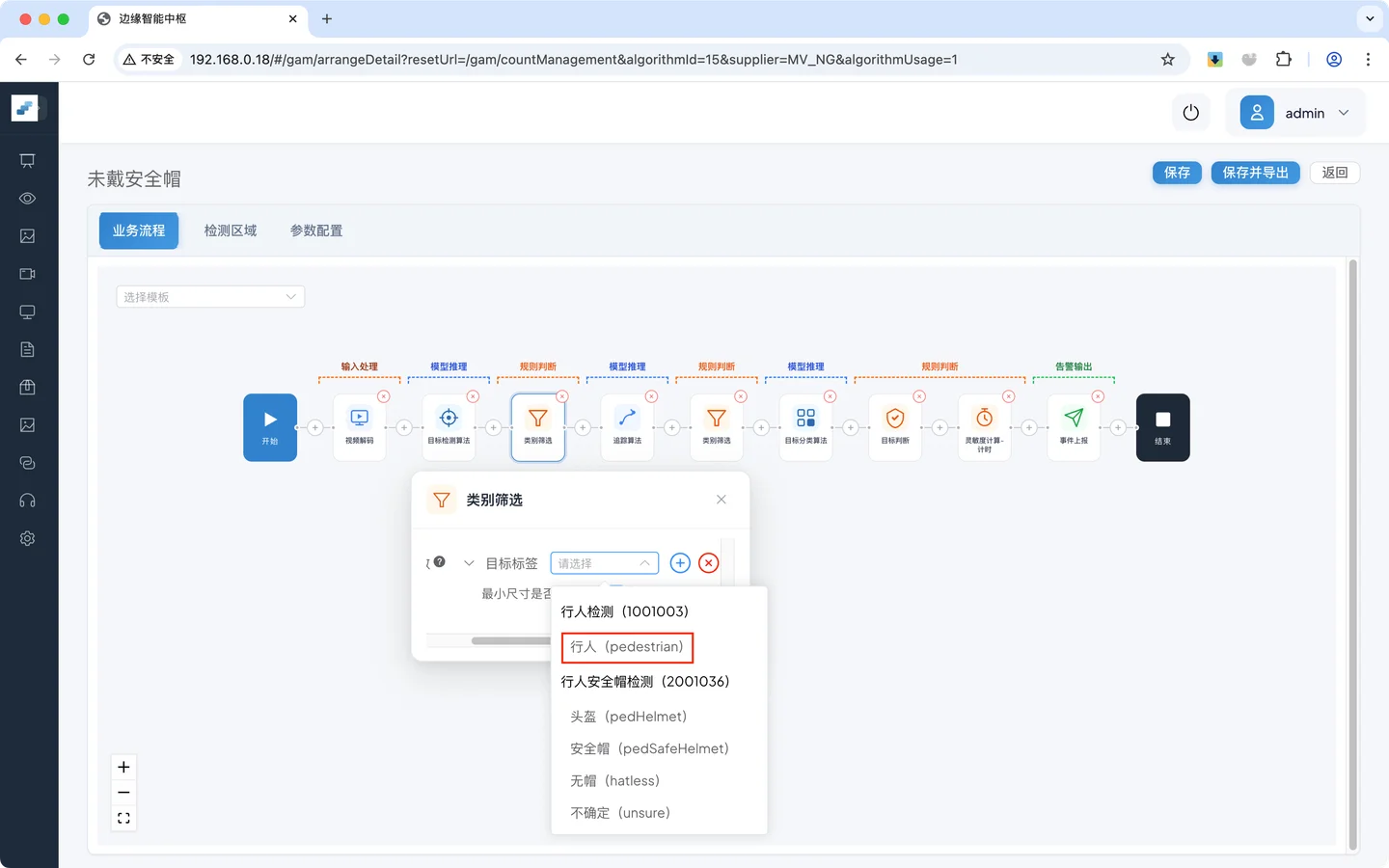
开启 **最小尺寸 **开关,小于该尺寸的预测结果都会被丢弃
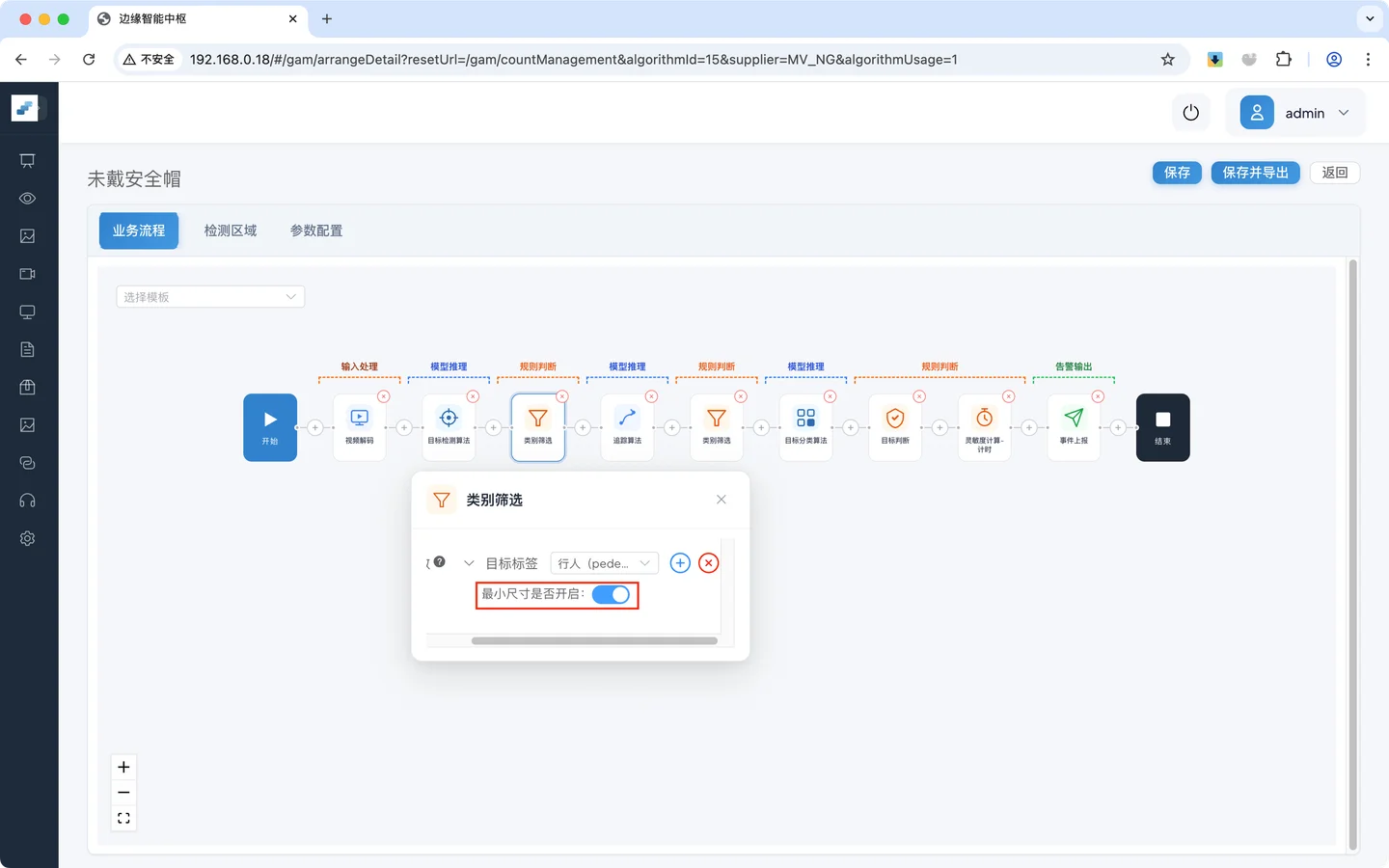
最小尺寸默认值是像素值 60*60 ,也可以自定义过滤的最小尺寸
2.2 配置关键参数
最小尺寸过滤原理:当设置最小尺寸为60时,则当检测目标的面积小于60*60时,会被过滤。
点击 **参数配置,**进入参数配置页面
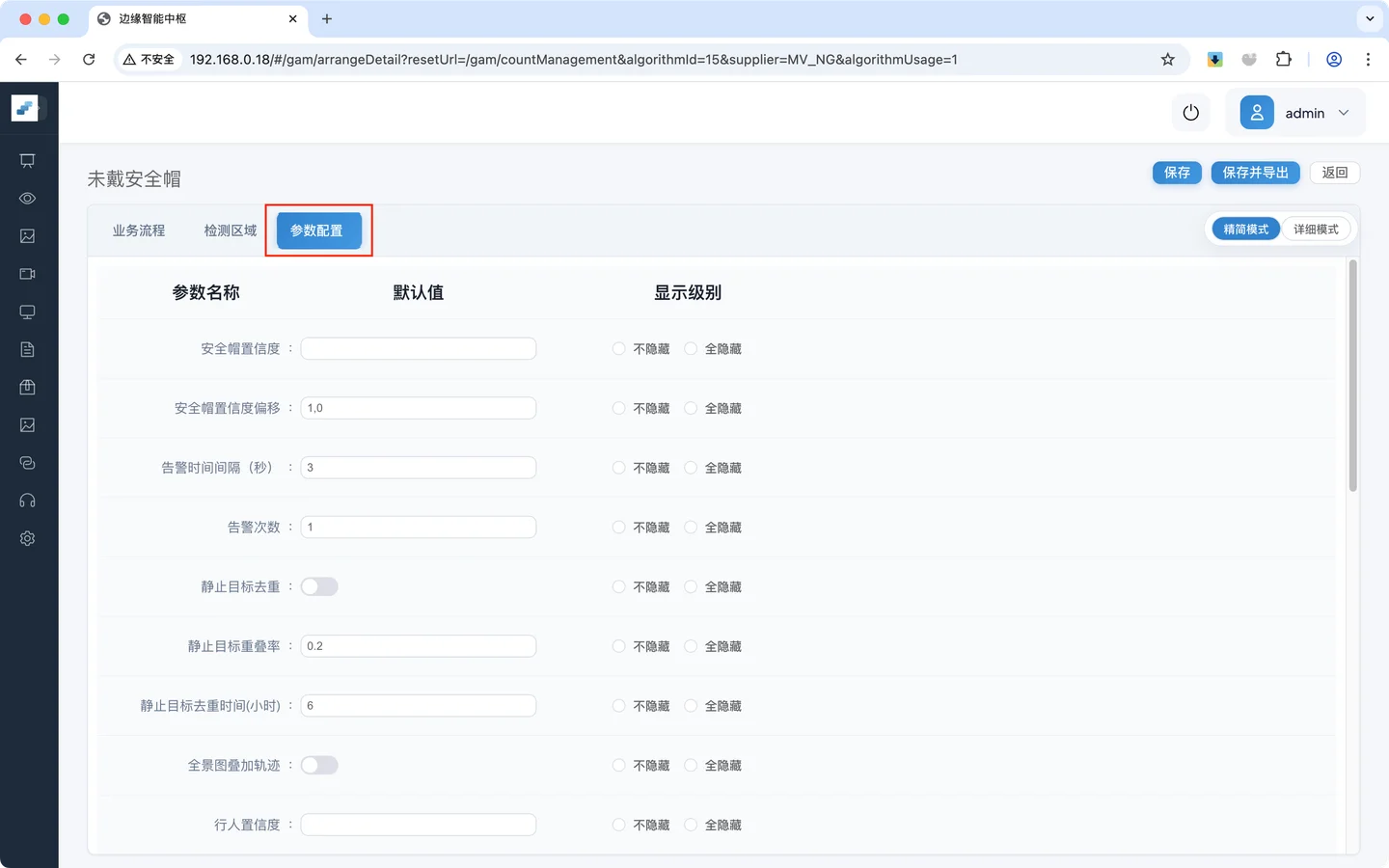
设置 最小行人尺寸 为40,即最小尺寸为 40 * 40
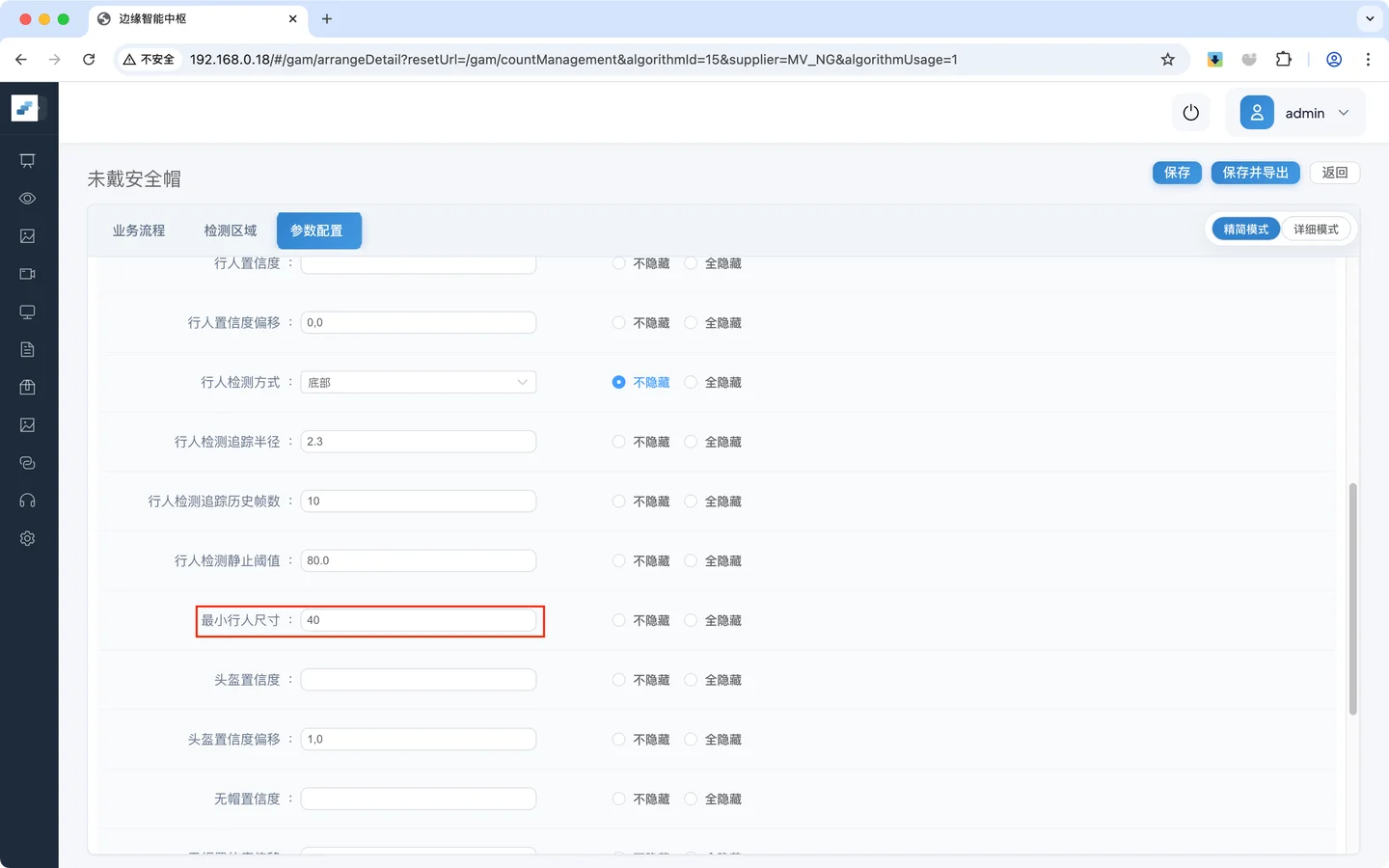
调参建议
可以先把最小尺寸调到
100,观察效果是否过强; 再逐步回落到40-60,找到当前场景下更平衡的阈值。
2.4 保存并验证
- 点击 **保存 **按钮保存在配置
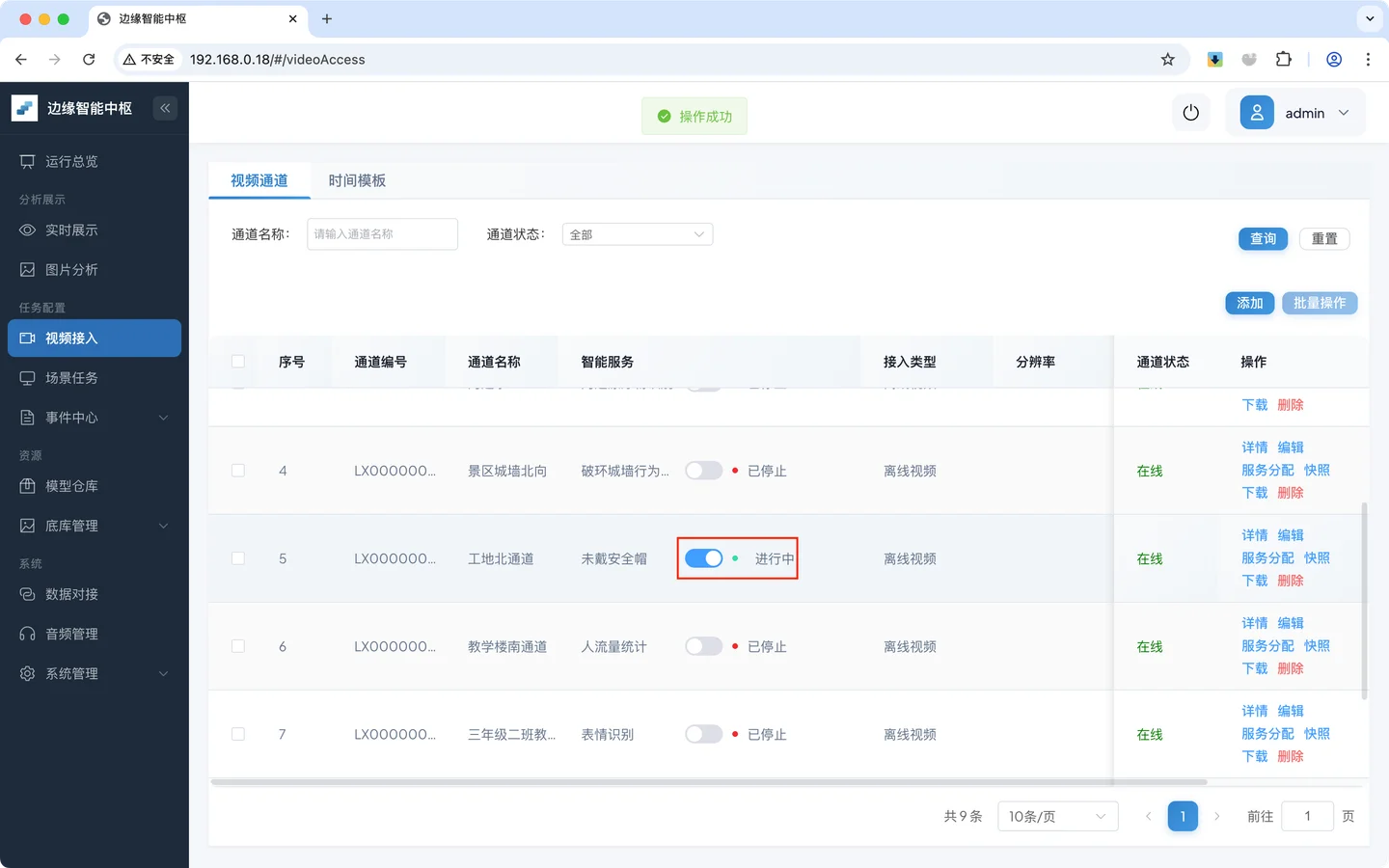
- 进入 视频接入 → **服务分配,**找到 **未戴安全帽 **通道
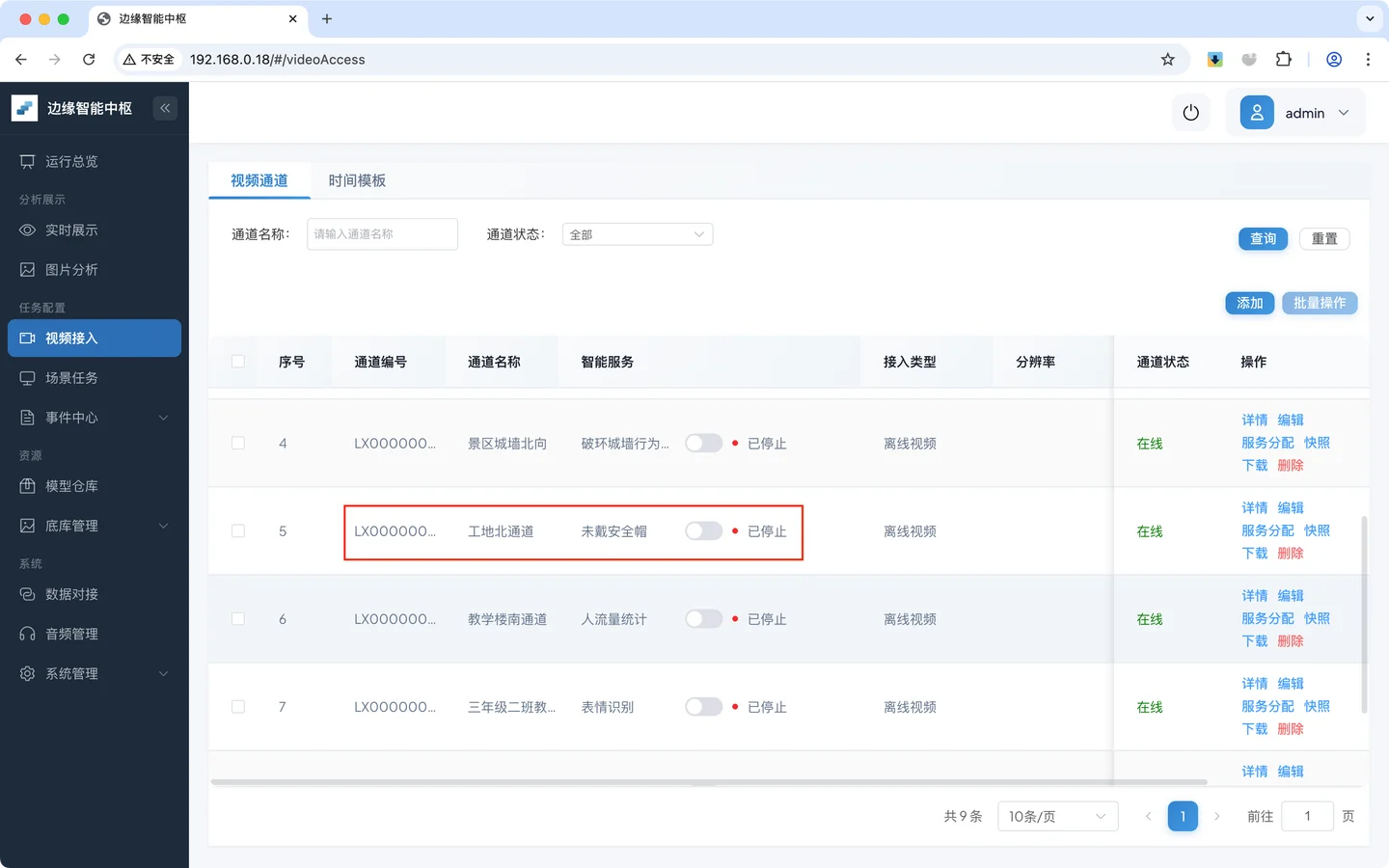
- 启动 未戴安全帽 服务
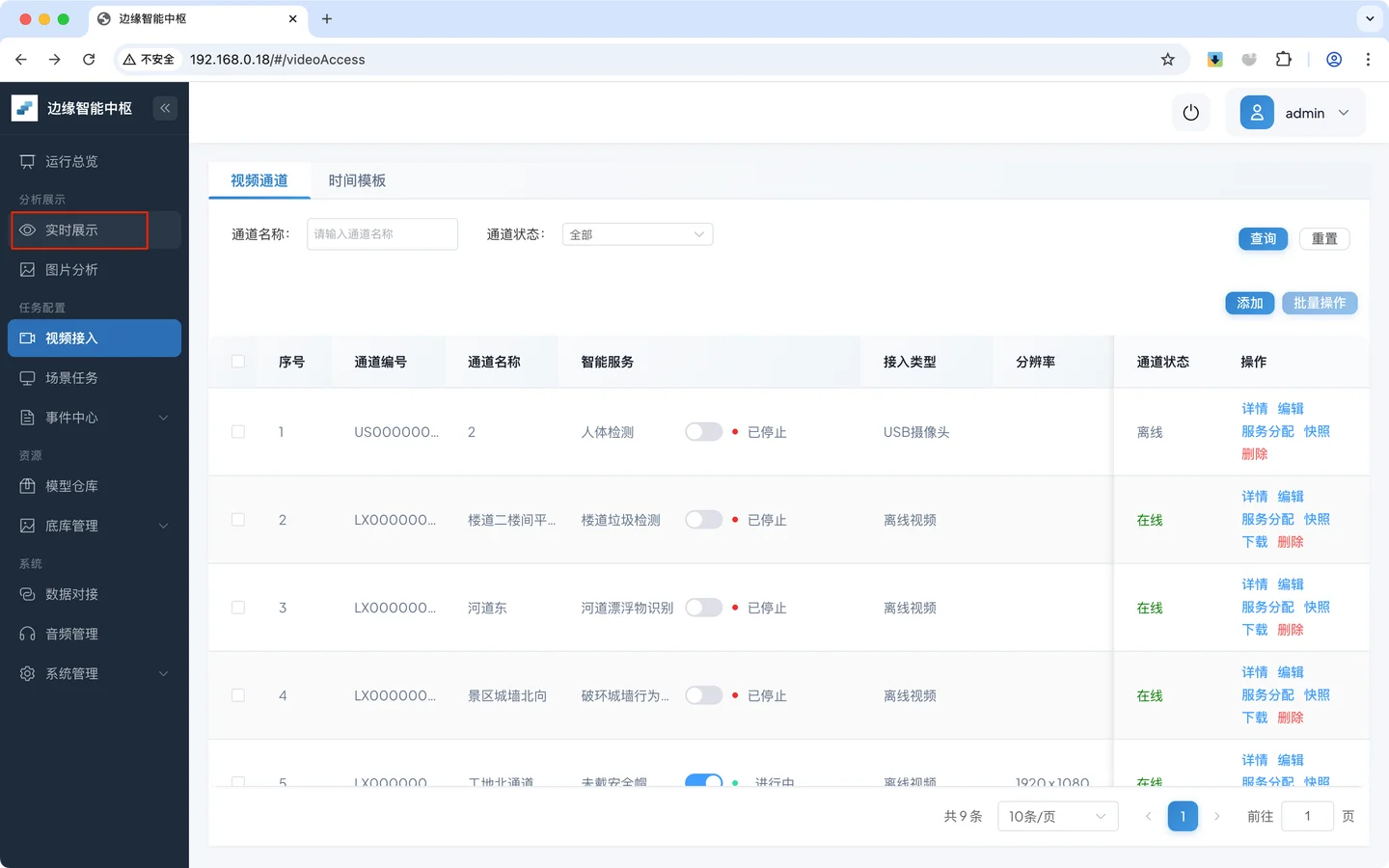
- 进入 实时展示 观察变化
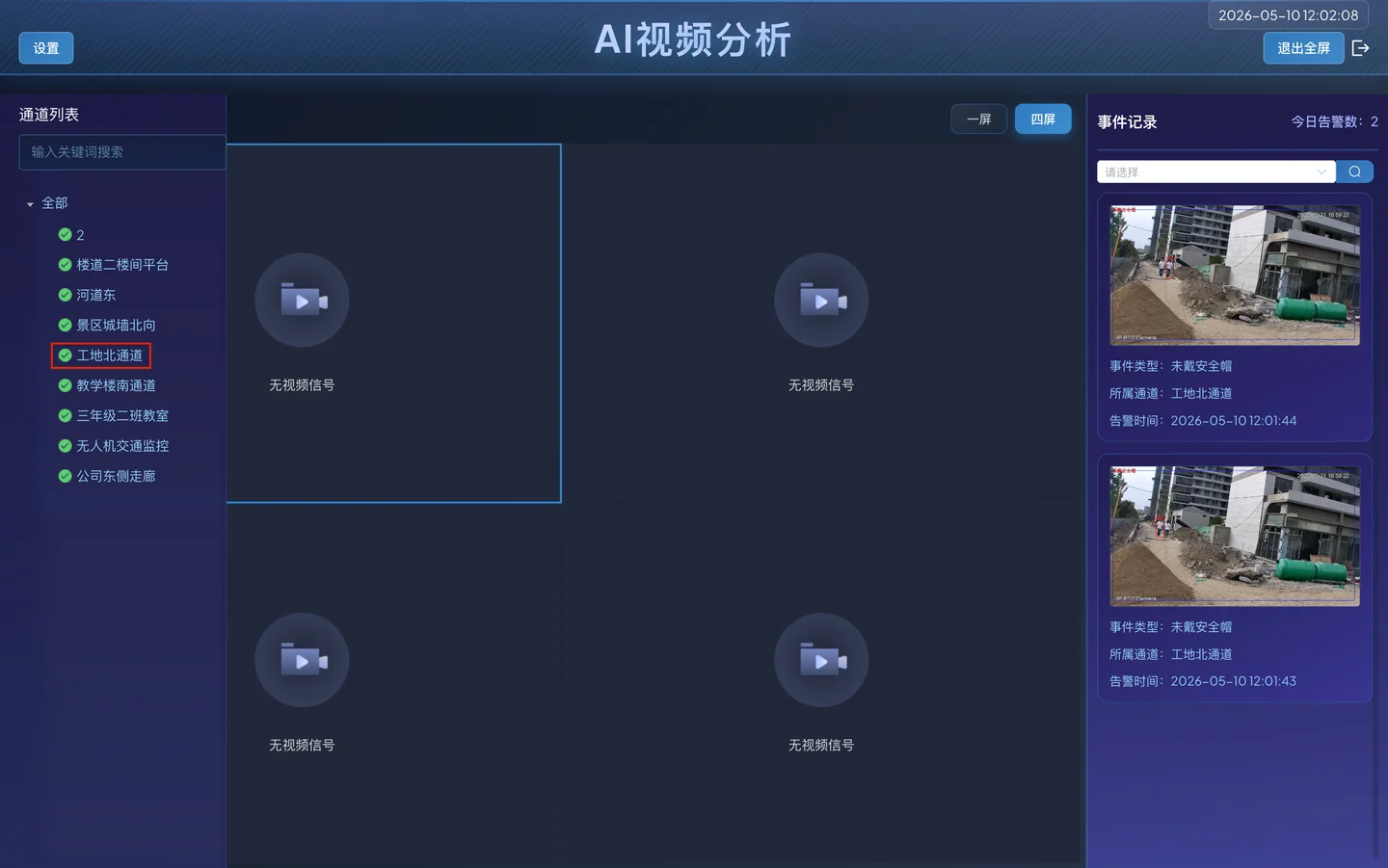
选择 **工地北通道 ,**并进入全屏
算法叠加可视化展示
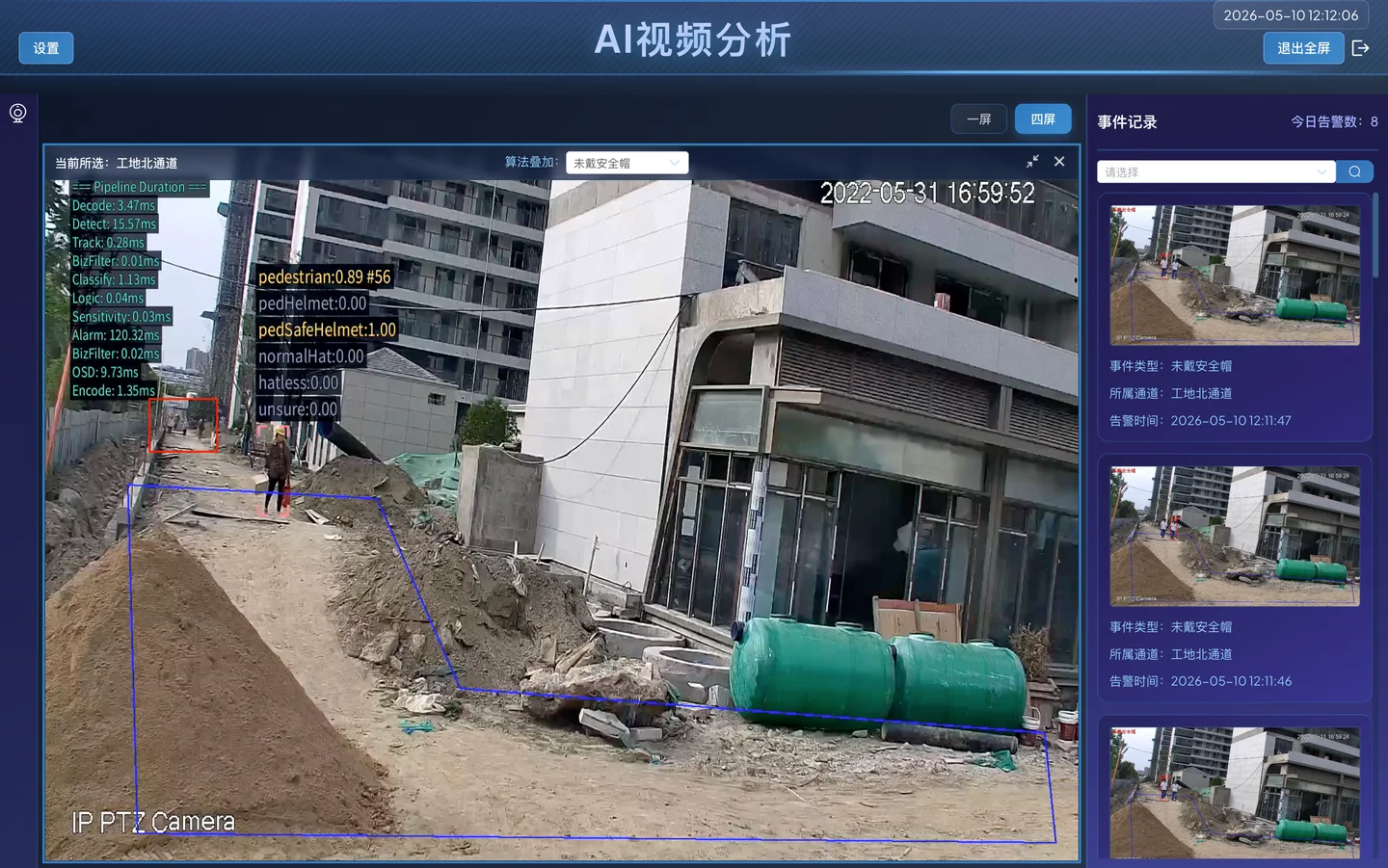
结果分析:
- 远处过小的人体(红色框标记)目标明显变多
- 近处清晰目标仍能正常检测和分类
- 误报数量下降
到这里,您已经完成了第一次 场景任务修改。 这个操作模式以后会反复出现:
打开现有 场景任务→ 增删节点 → 配置参数 → 保存 → 验证第三章:从零创建一个新的场景任务
前两章解决的是“看懂”和“会改”。本章解决的是“自己搭”。
我们仍然不从完全陌生的空白开始,而是沿用“参照现有结构”的方法。
场景说明
创建一条新的 **区域入侵检测 **场景任务:
- 检测画面中的人员
- 判断人员是否进入指定区域
- 连续命中后触发告警
- 在实时展示中看到框和标签
这个例子有两个好处:
- 只使用系统内置能力,门槛低
- 同时覆盖“检测 + 区域规则 + 告警 + 可视化”这条完整闭环
3.1 创建新算法
- 进入 **场景任务 **
- 点击 **新建任务 **
- 填写基础信息
| 字段 | 填写内容 |
|---|---|
| 任务名称 | 区域入侵检测 |
| 数据源类型 | 视频分析 |
| 任务类型 | 检测/分析 |
点击 确定 保存任务。
3.2 搭建 场景任务的算法编排
准备工作
点击 算法编排 进入空白编排页面
空白的编排链路只包含开始和结束节点
两个节点之间的加号按钮用于添加各种组件
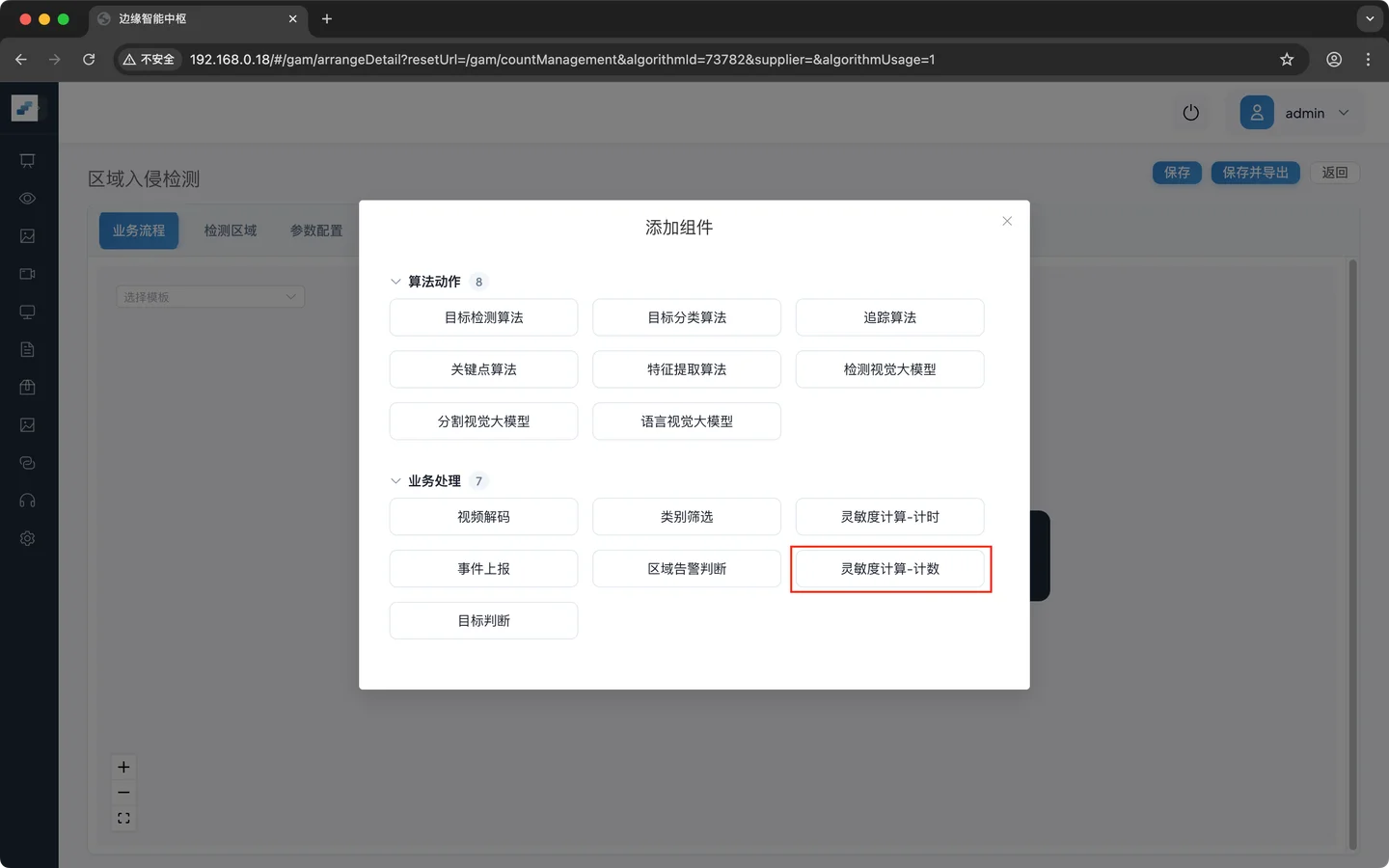
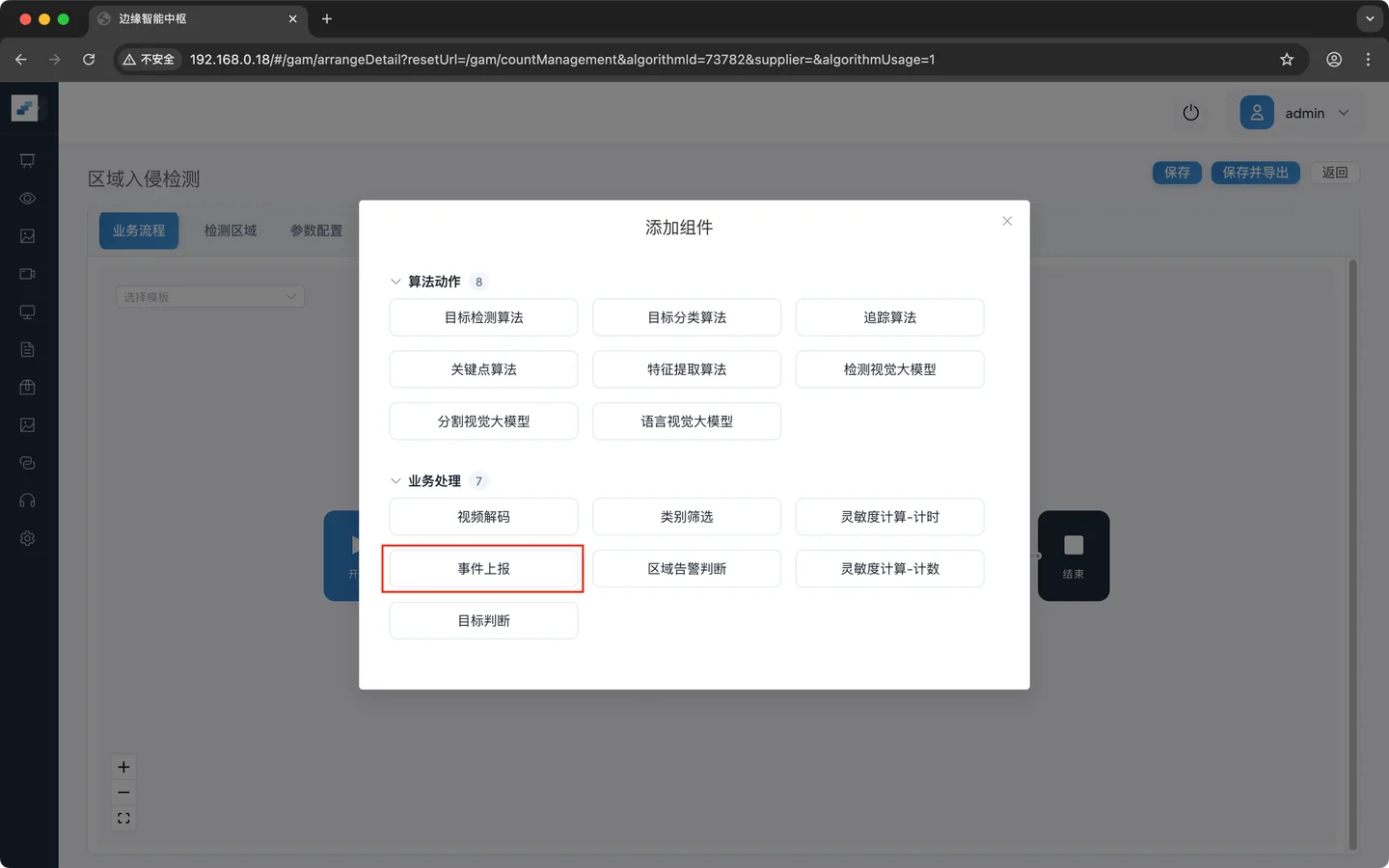
点击 加号 之后弹出操作选项,**添加组件 **用于添加各种算法组件
点击 添加组件 ,弹出面板显示所有的组件。面板中的组件详细信息可参考 附录A 节点速查表
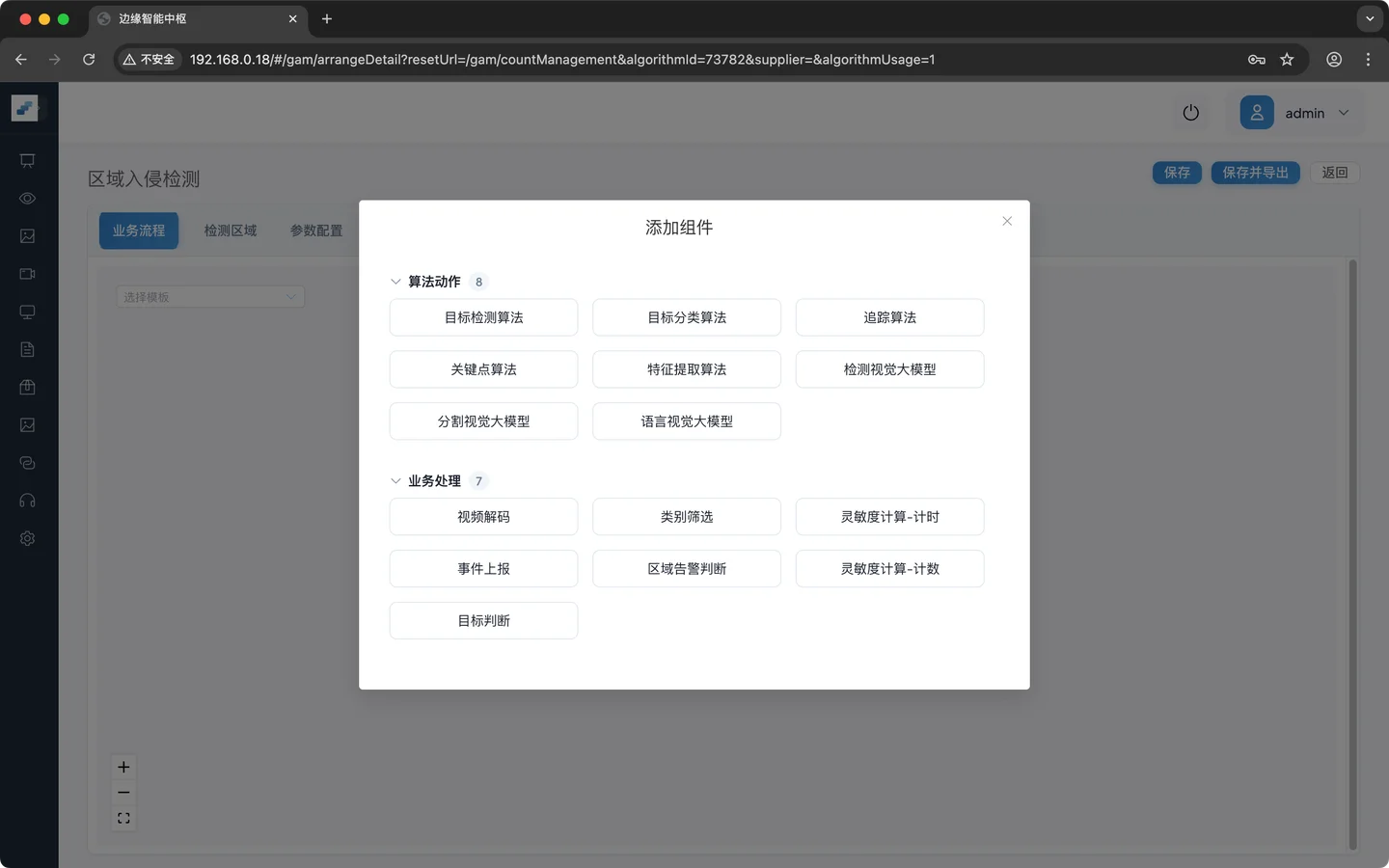
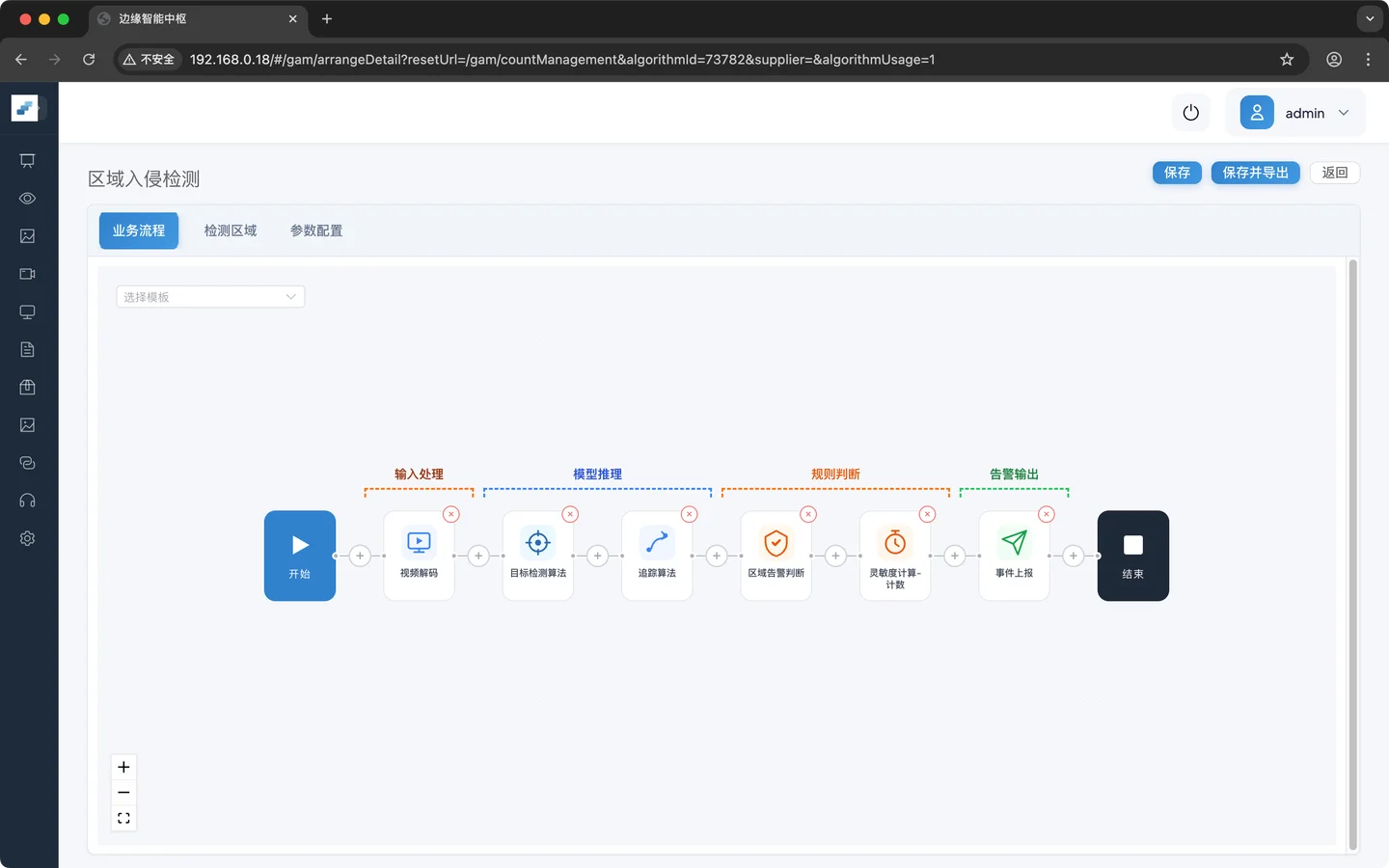
按下面顺序添加节点:
视频解码 → 目标检测 → 目标追踪 → 区域判定 → 灵敏度计算 → 事件上报第一步:添加视频解码
视频解码节点是所有 场景任务的起点,作用是将视频流解码为逐帧图像,视频流可以是RTSP流也可以是视频文件
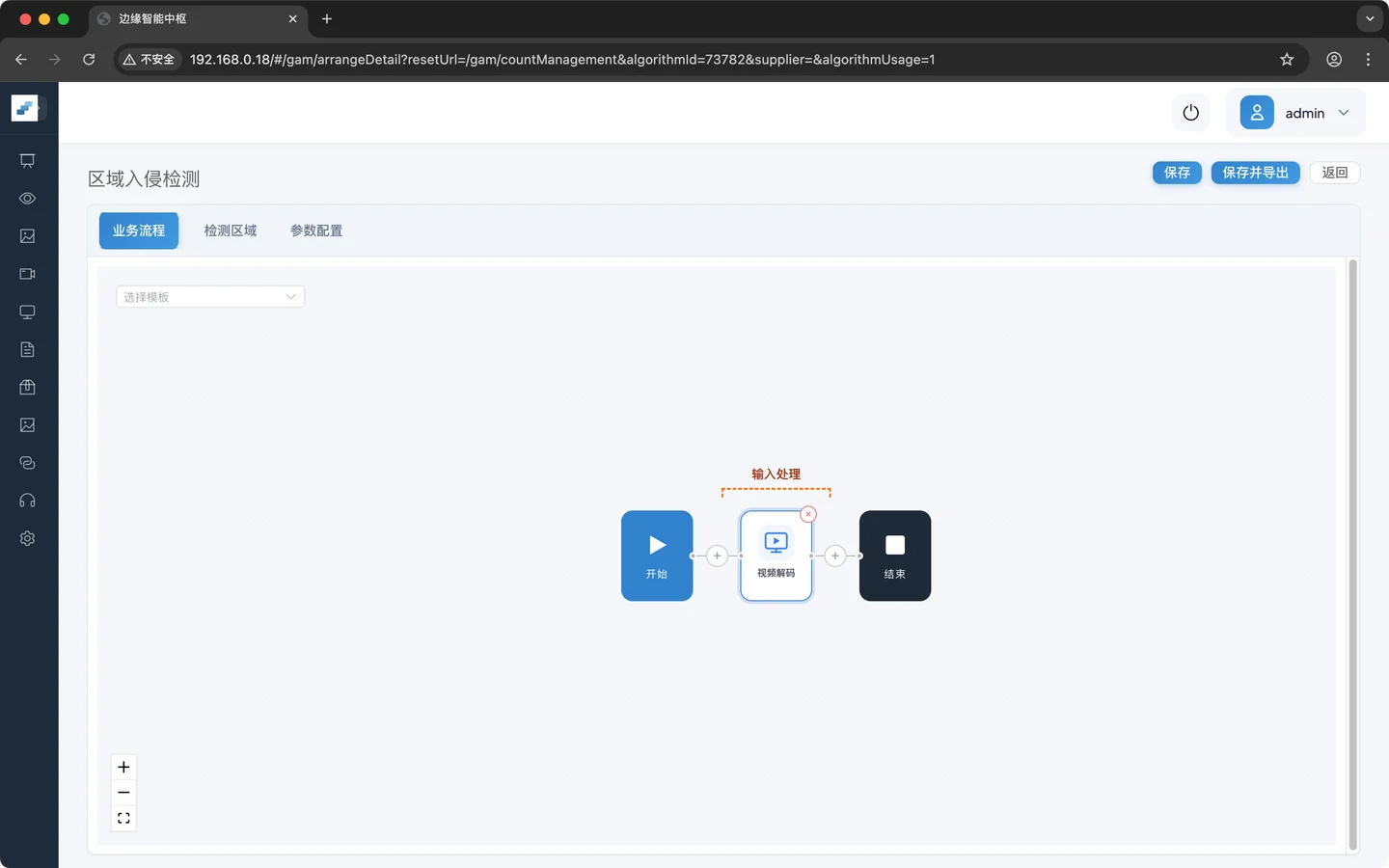
业务逻辑配置
点击 视频解码 展示需要配置的参数。由于视频解码没有配置项,所以空白。
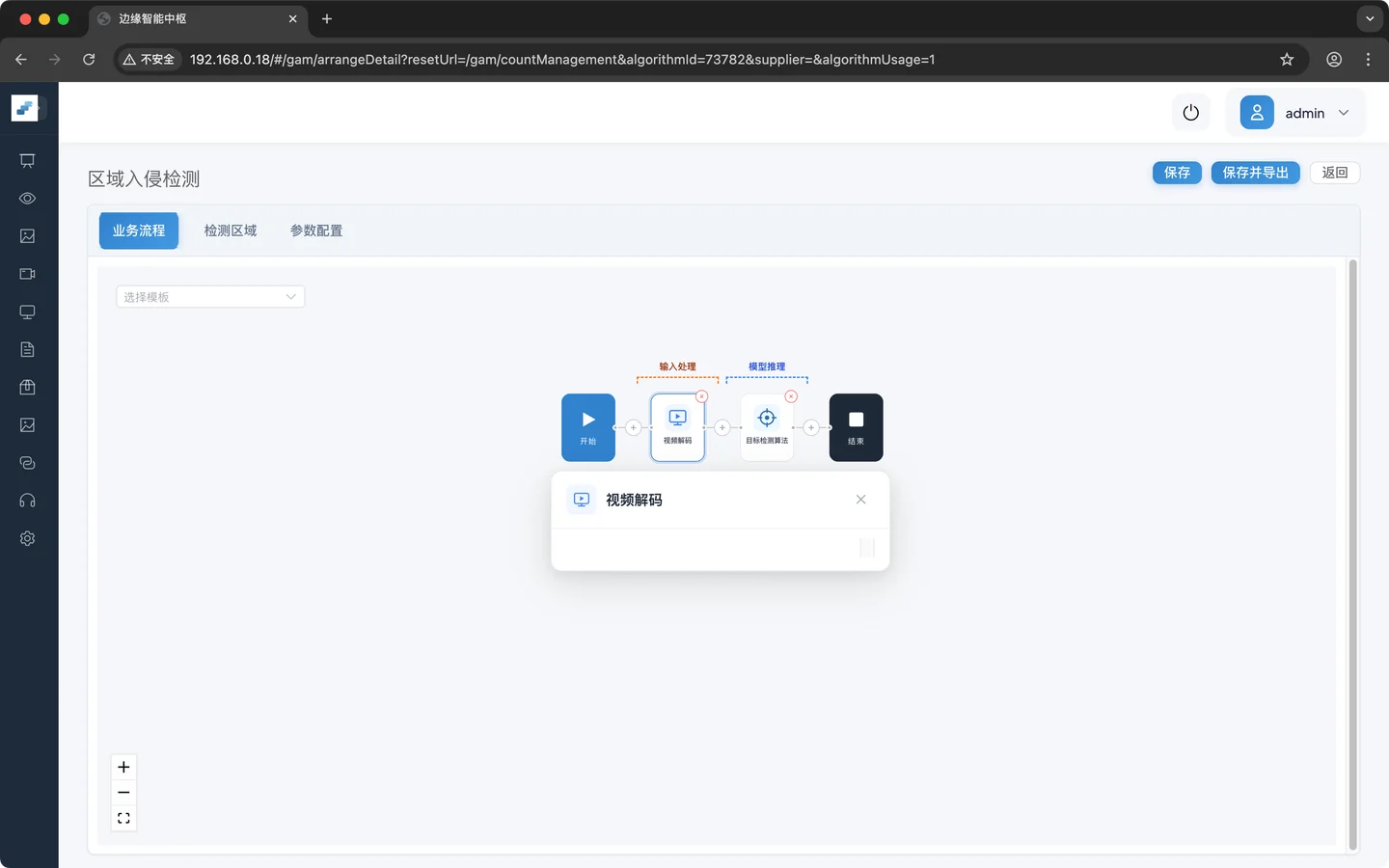
第二步:添加目标检测
解码后的图像输入目标检测模型,输出目标位置信息和类别信息
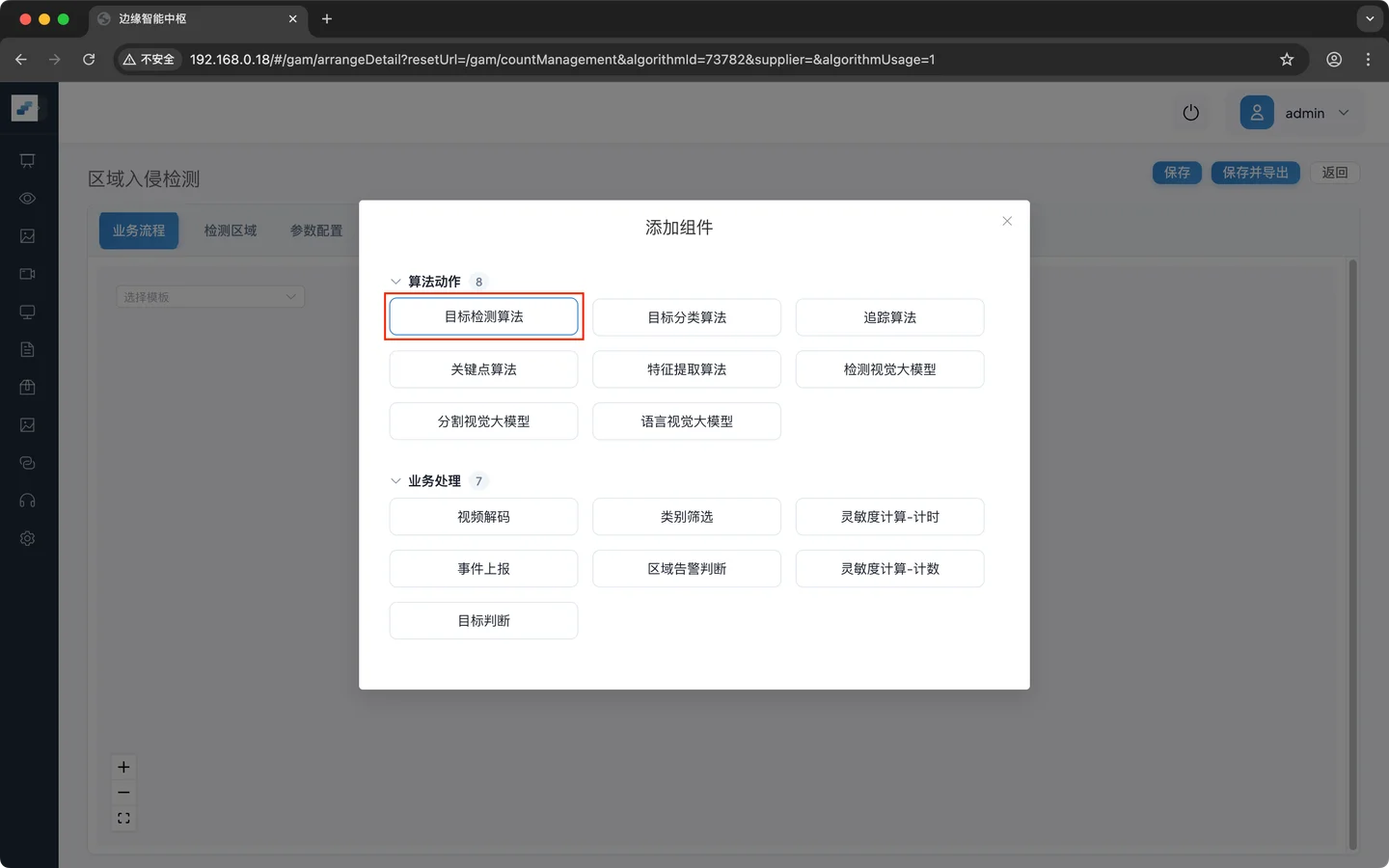
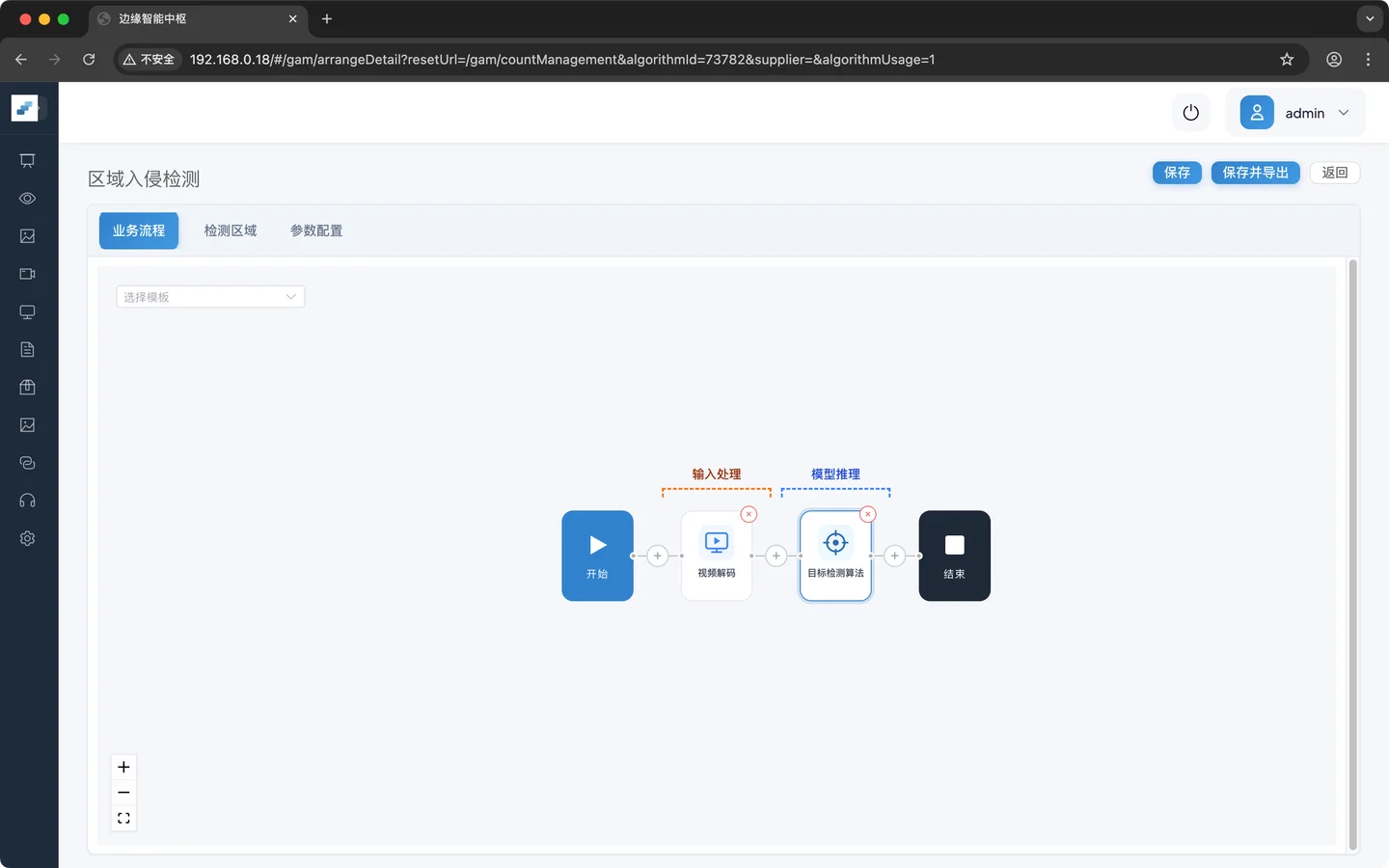
业务逻辑配置
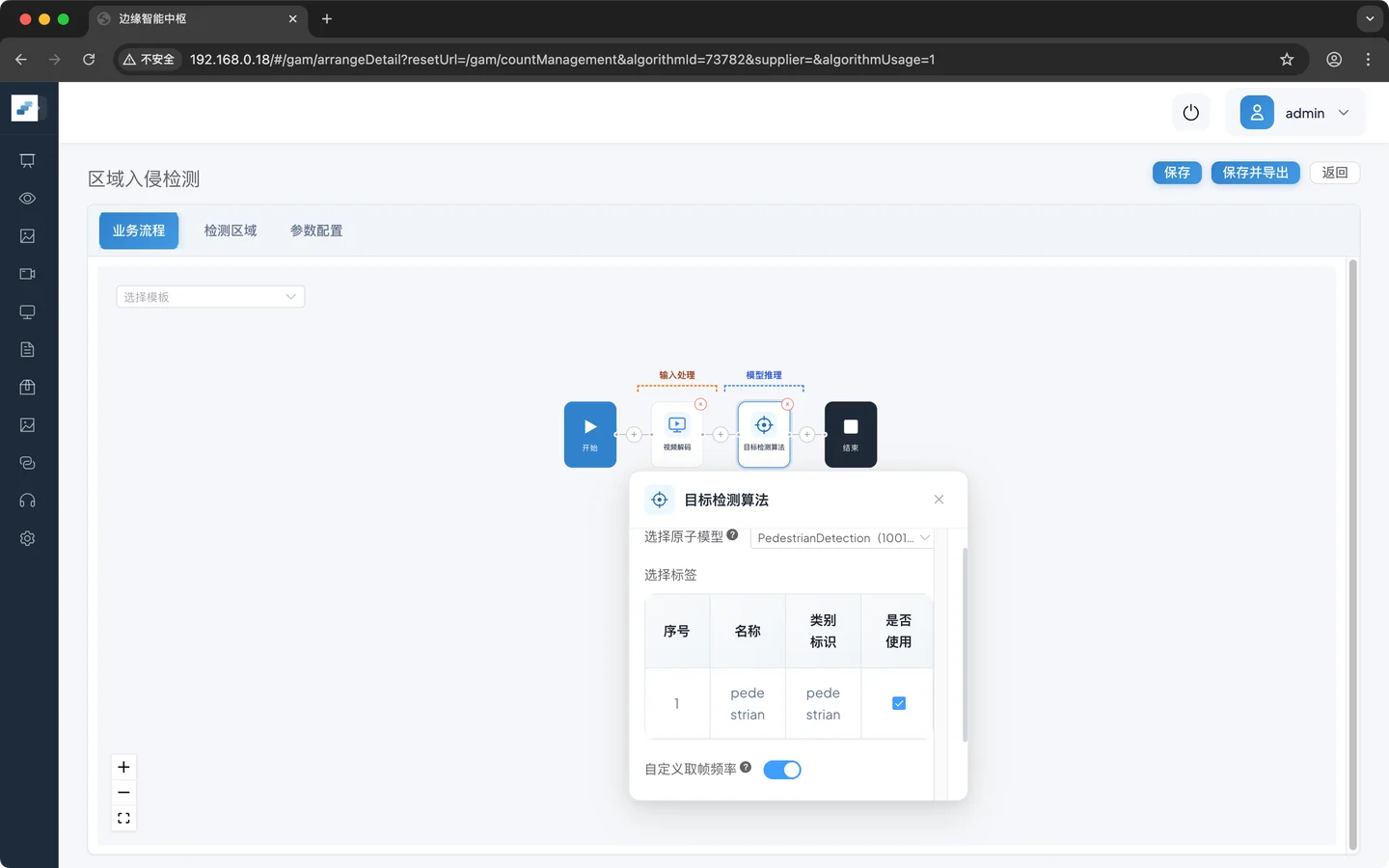
原子模型:PedestrianDetection (行人检测模型)
选择标签:Pedstrian (行人)
自定义取帧频率:开启
第三步:添加目标追踪
对检测到的目标进行追踪,让前后帧的同一个目标能关联起来,为后续业务逻辑提供身份ID
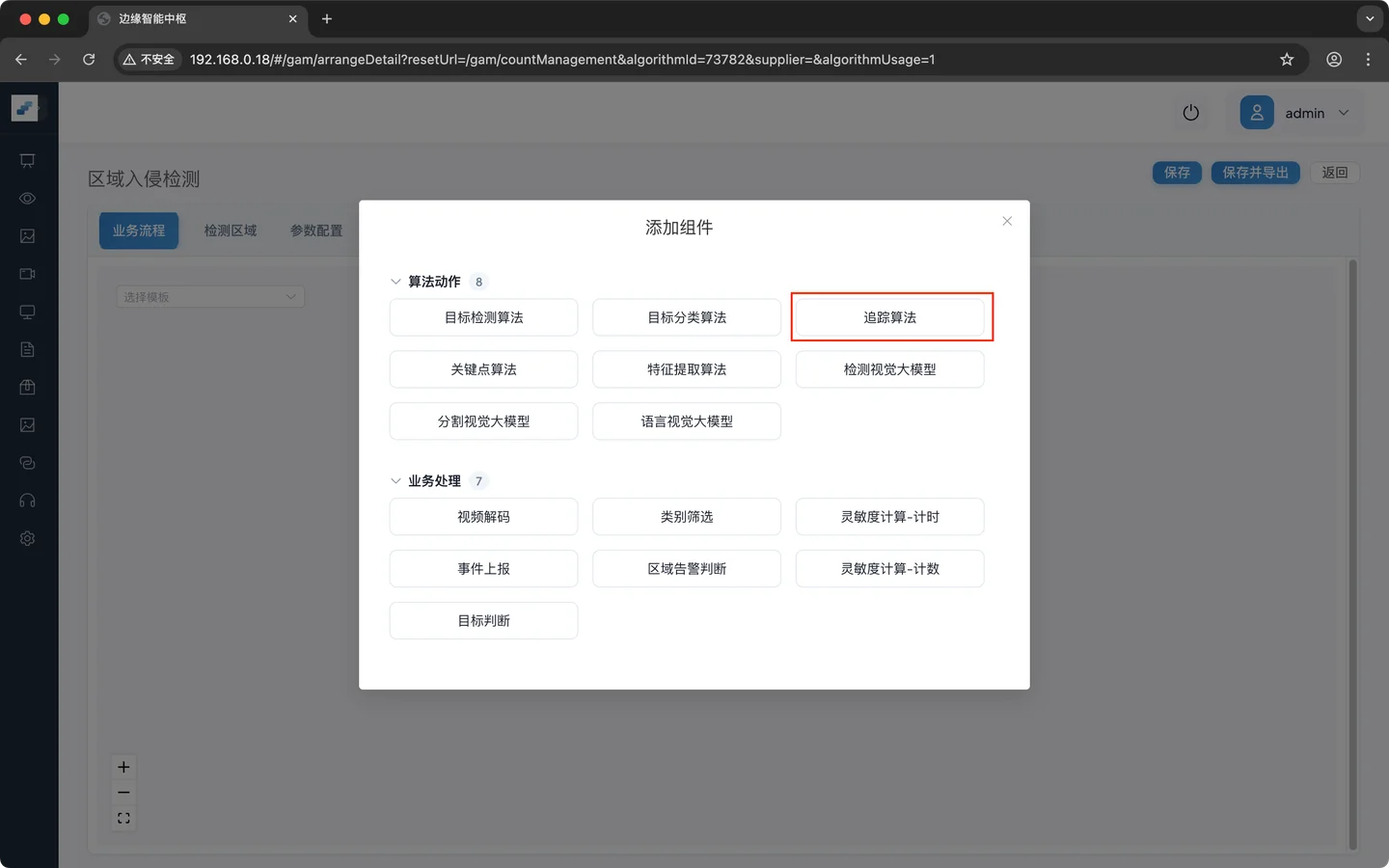
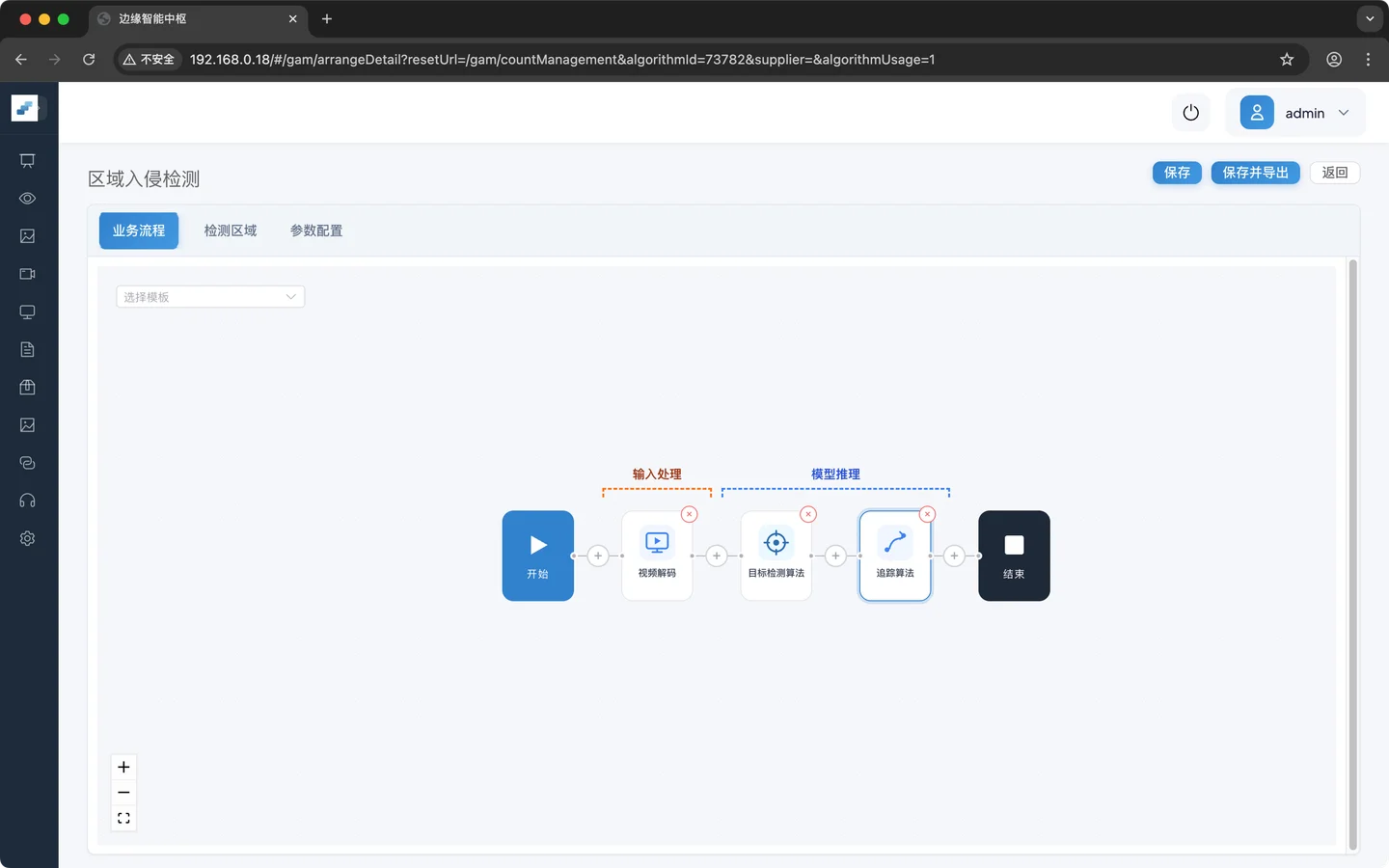
业务逻辑配置
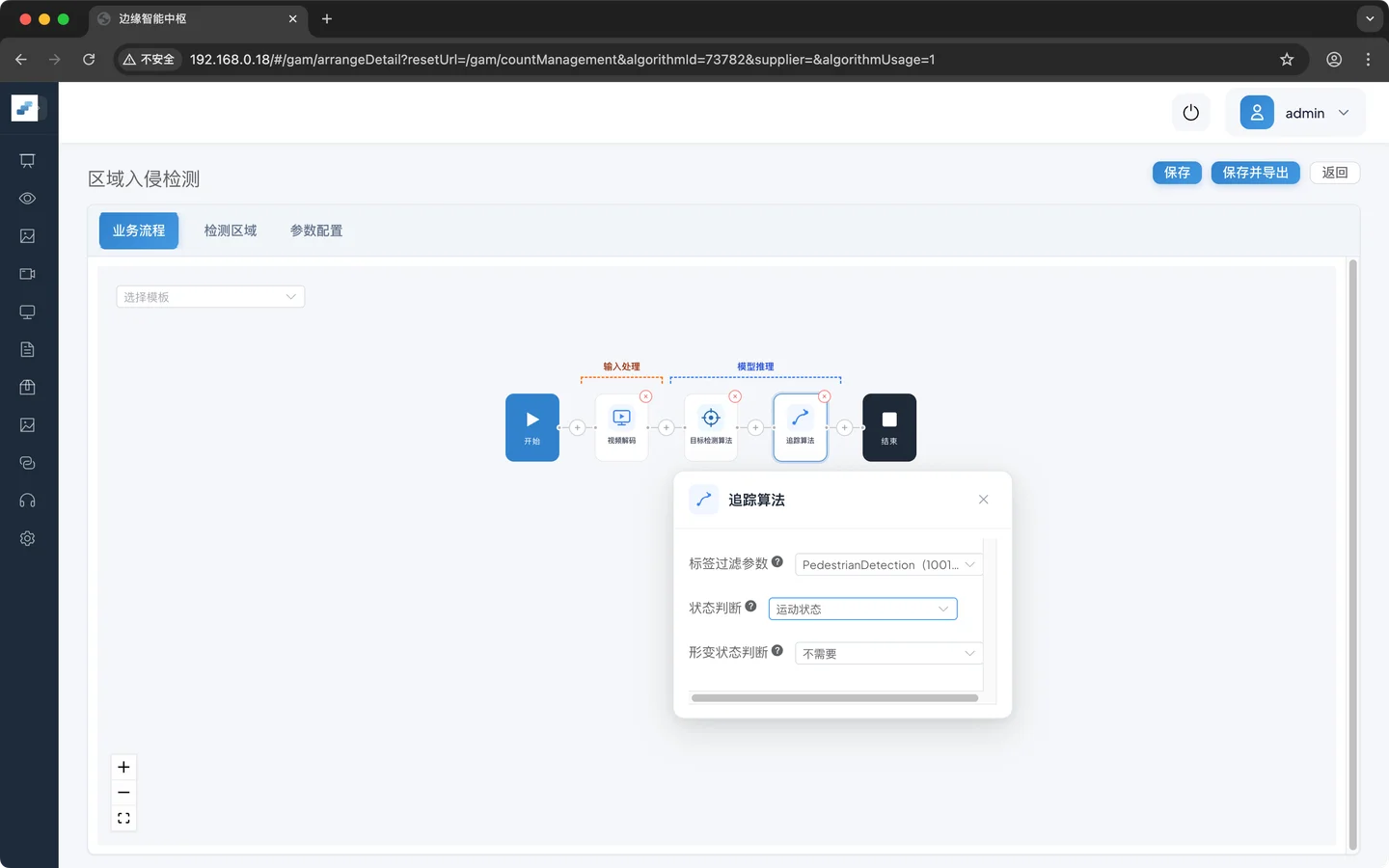
标签过滤参数:PedestrianDetection,追踪该标签
状态判断:运动状态,
形变状态判断:不需要
第四步:添加区域判定
绘制一个区域用于实现业务中的入侵范围,进入该区域中触发告警事件
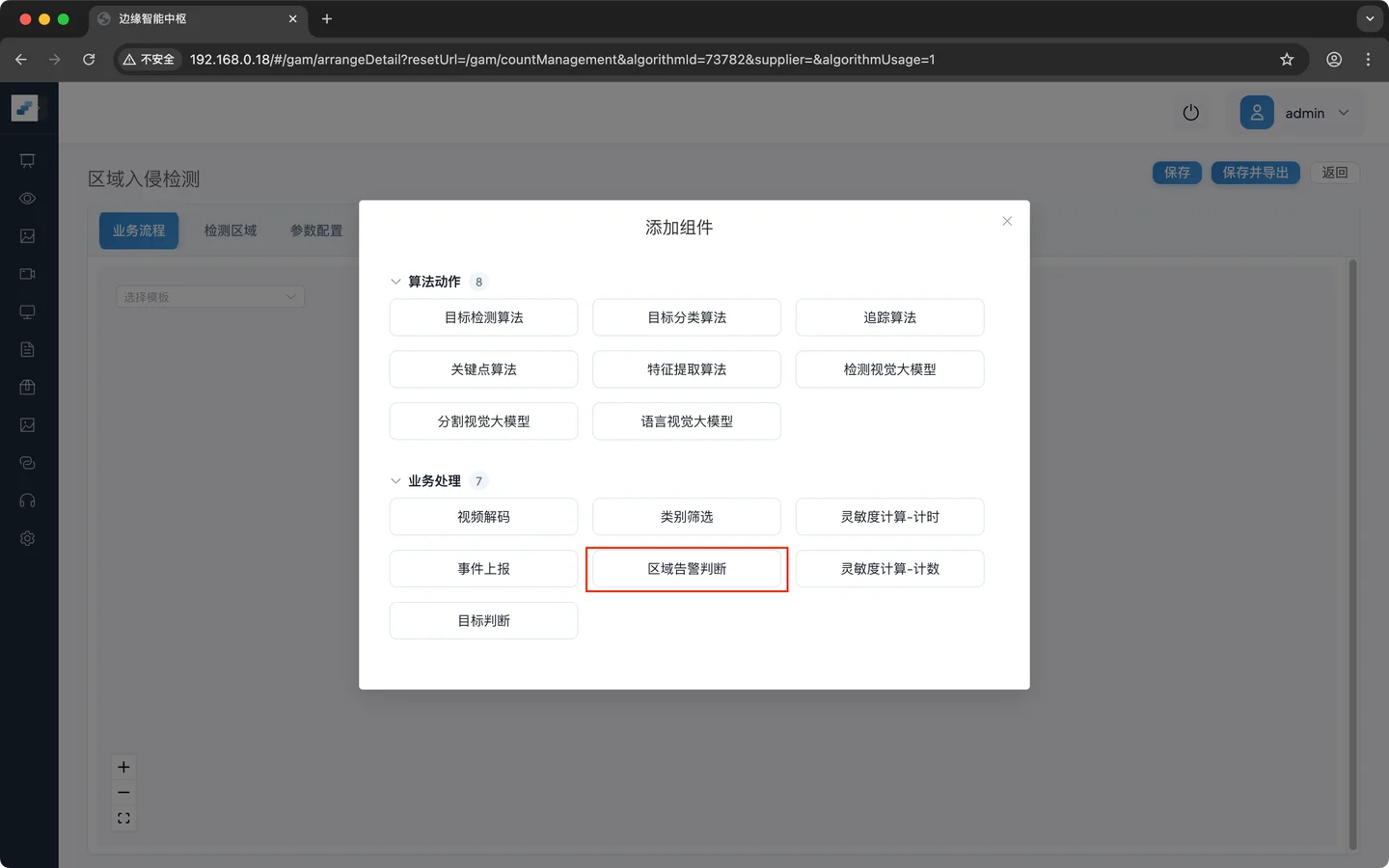
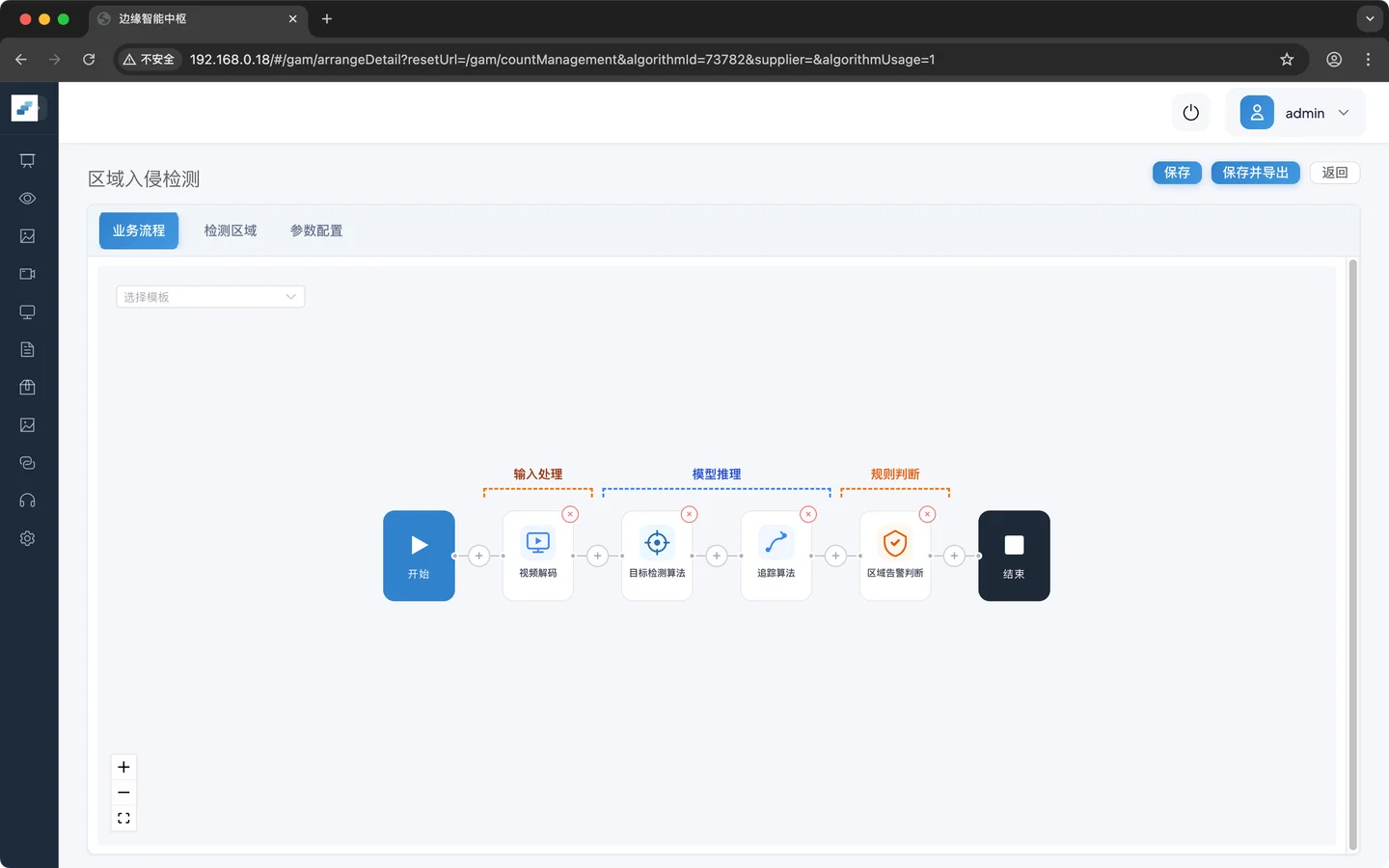
业务逻辑配置
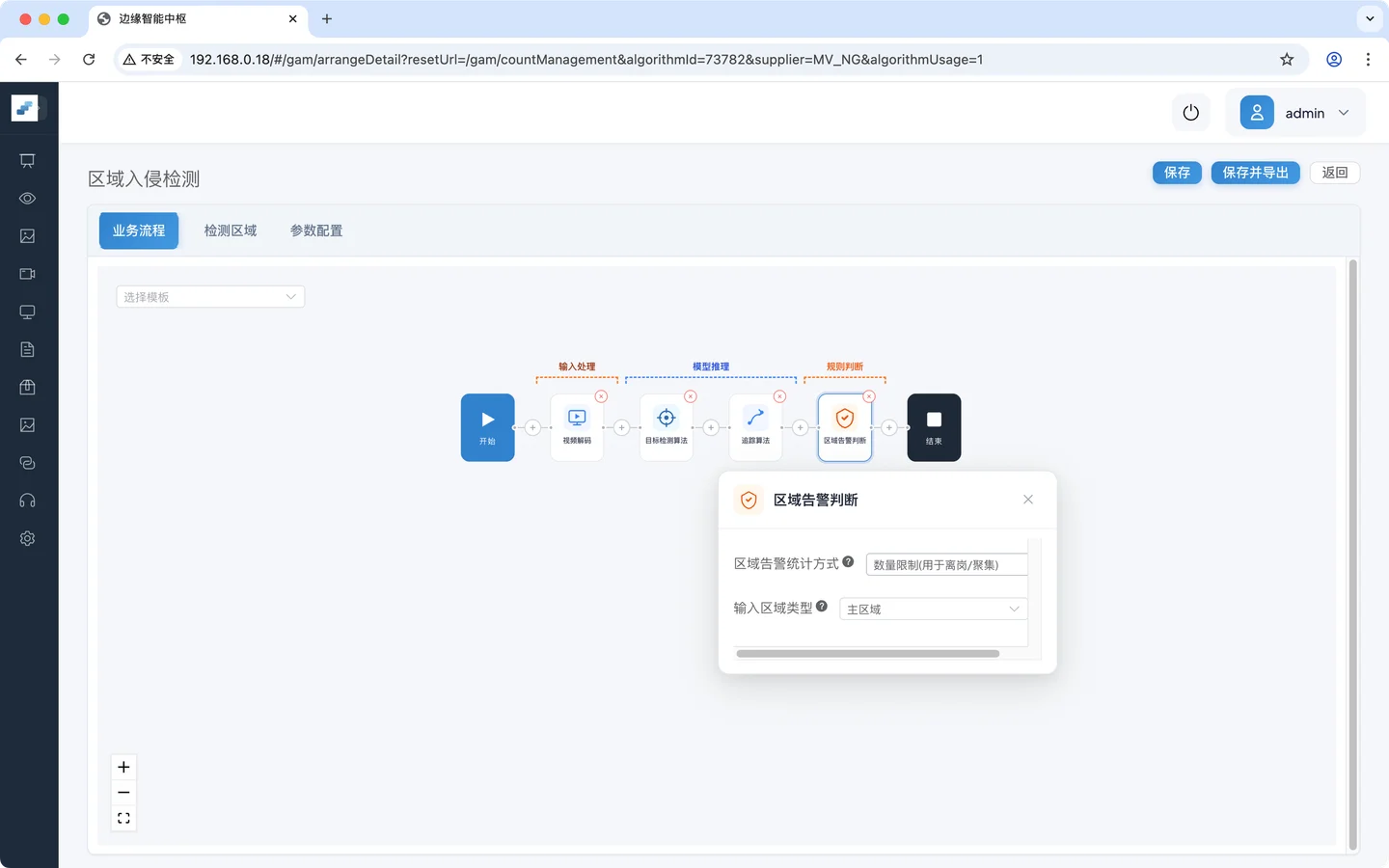
区域告警统计:数量限制(用于离岗/聚集)
输入区域类型:主区域
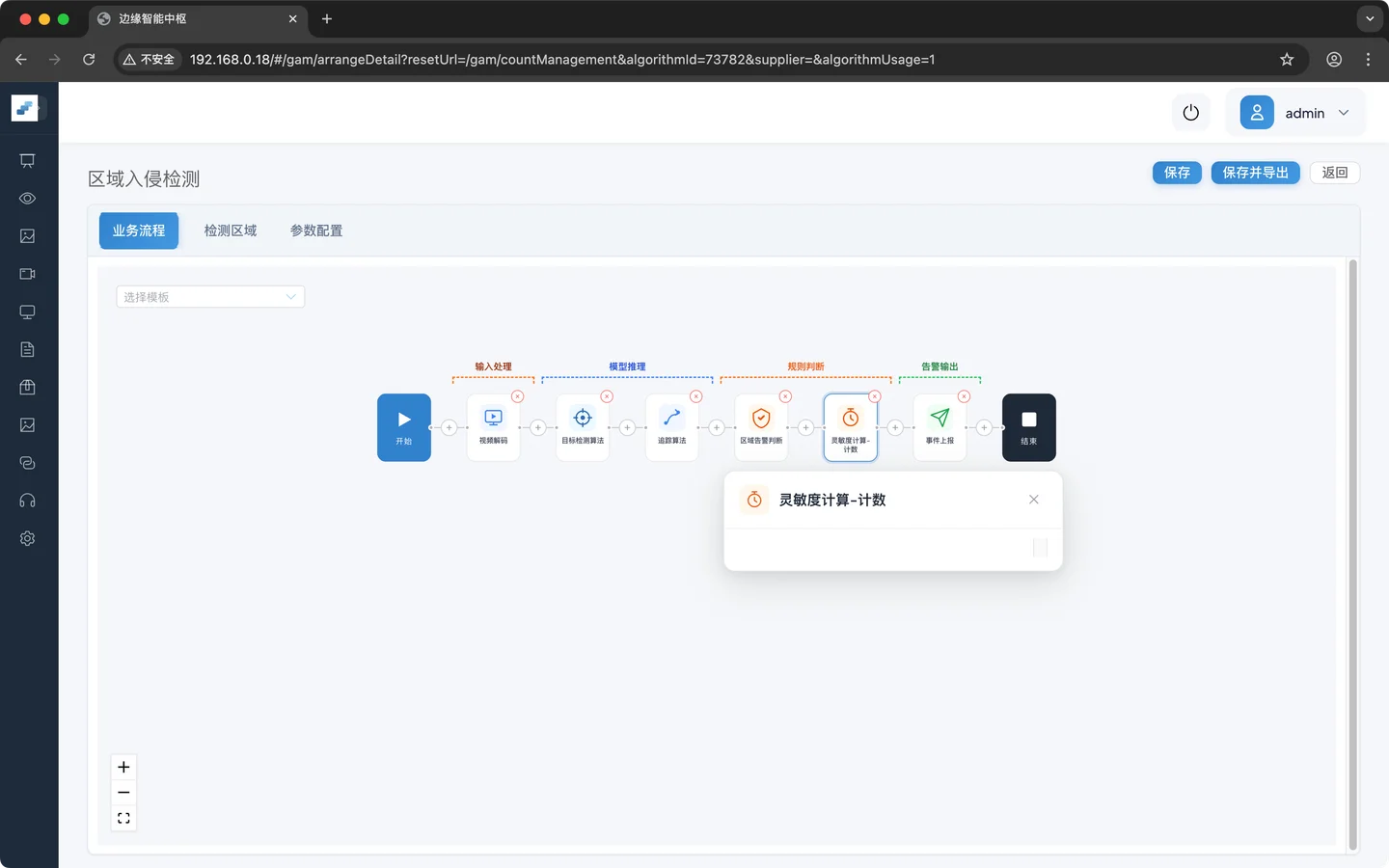
第五步:添加灵敏度计算
检测单帧就触发告警的误报较高,可以通过灵敏度来检测误报,具体实现就是多帧累积后再触发告警
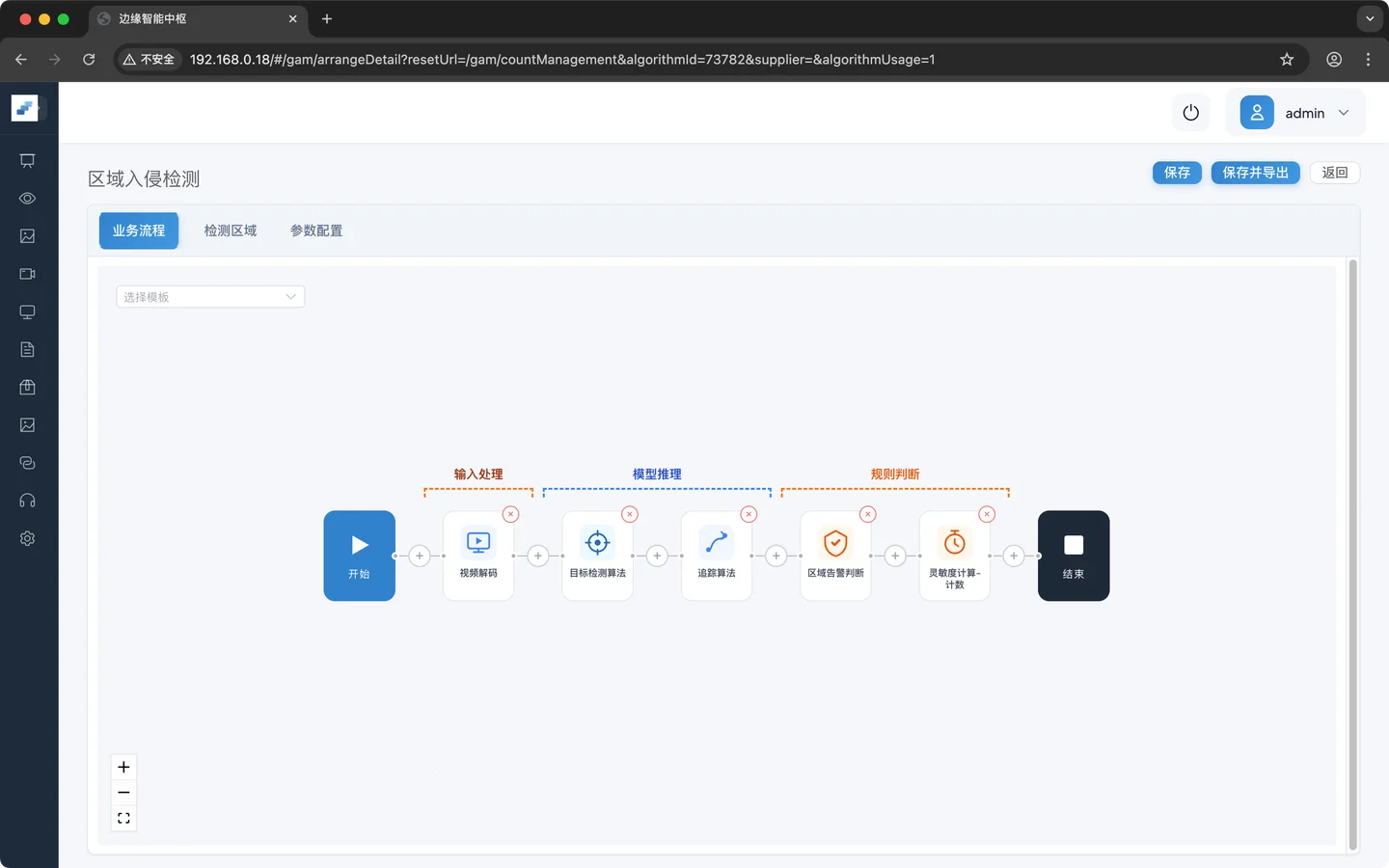
业务逻辑配置
第六步:添加事件上报
产生的告警事件上报给系统用于统计或及时推送终端
业务逻辑配置
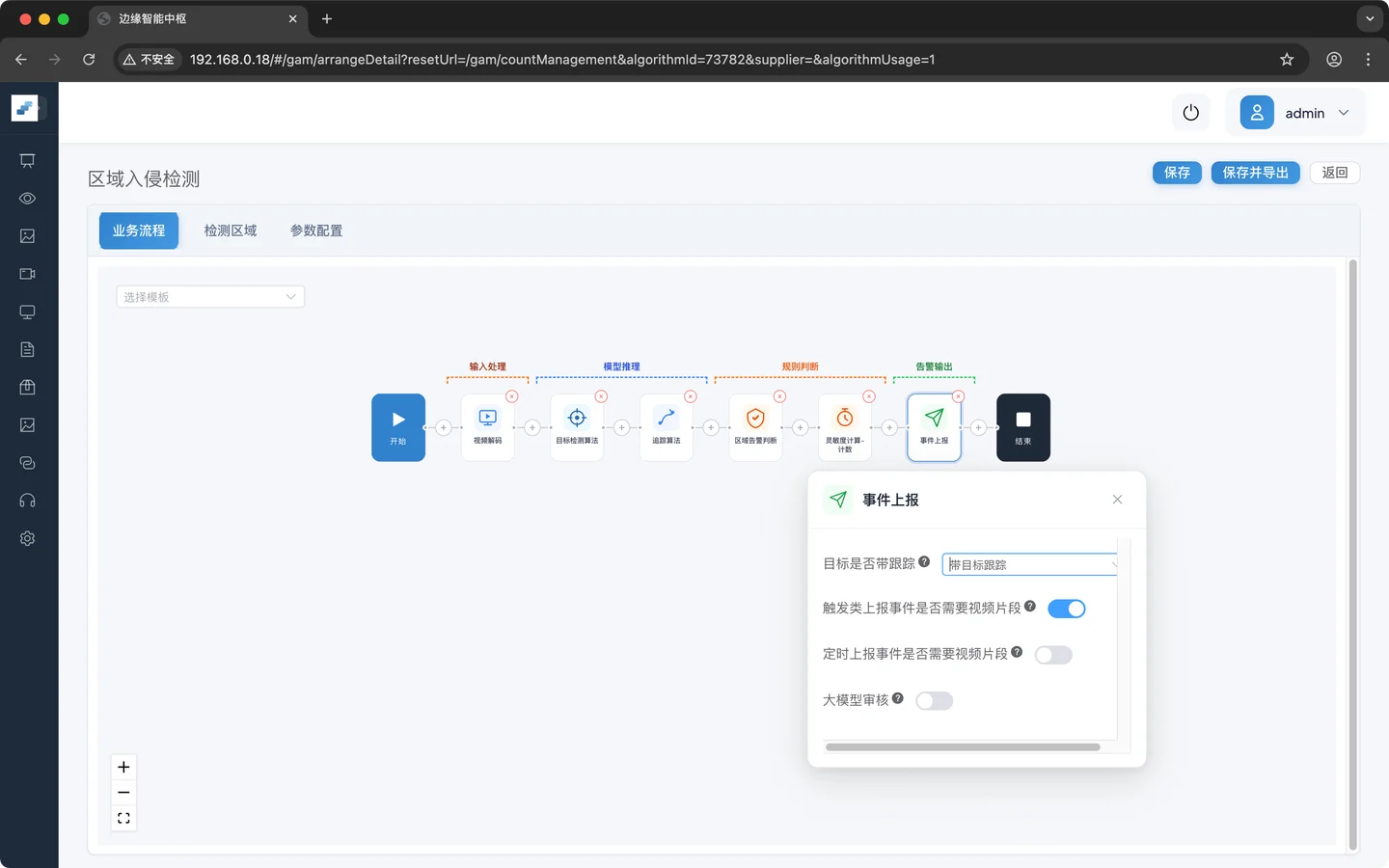
目标知否带跟踪:带目标跟踪
触发类上报时间是否需要视频片段:开启
定时上报事件是否需要视频片段:不开启
大模型审核:不开启
到这里一个完整的入侵检测编排场景任务就已经配置好了,下面对每一个节点配置详细的控制参数
3.4 配置关键参数
在上一个小节中实现了业务逻辑的编排,在该流程中用于控制业务逻辑的关键参数都是使用默认值。想要打造一个准确率高、误报率低的检测流程还需要精细化控制关键参数。本小节实现业务逻辑中关键参数的配置
点击 参数配置 切换到关键参数页面
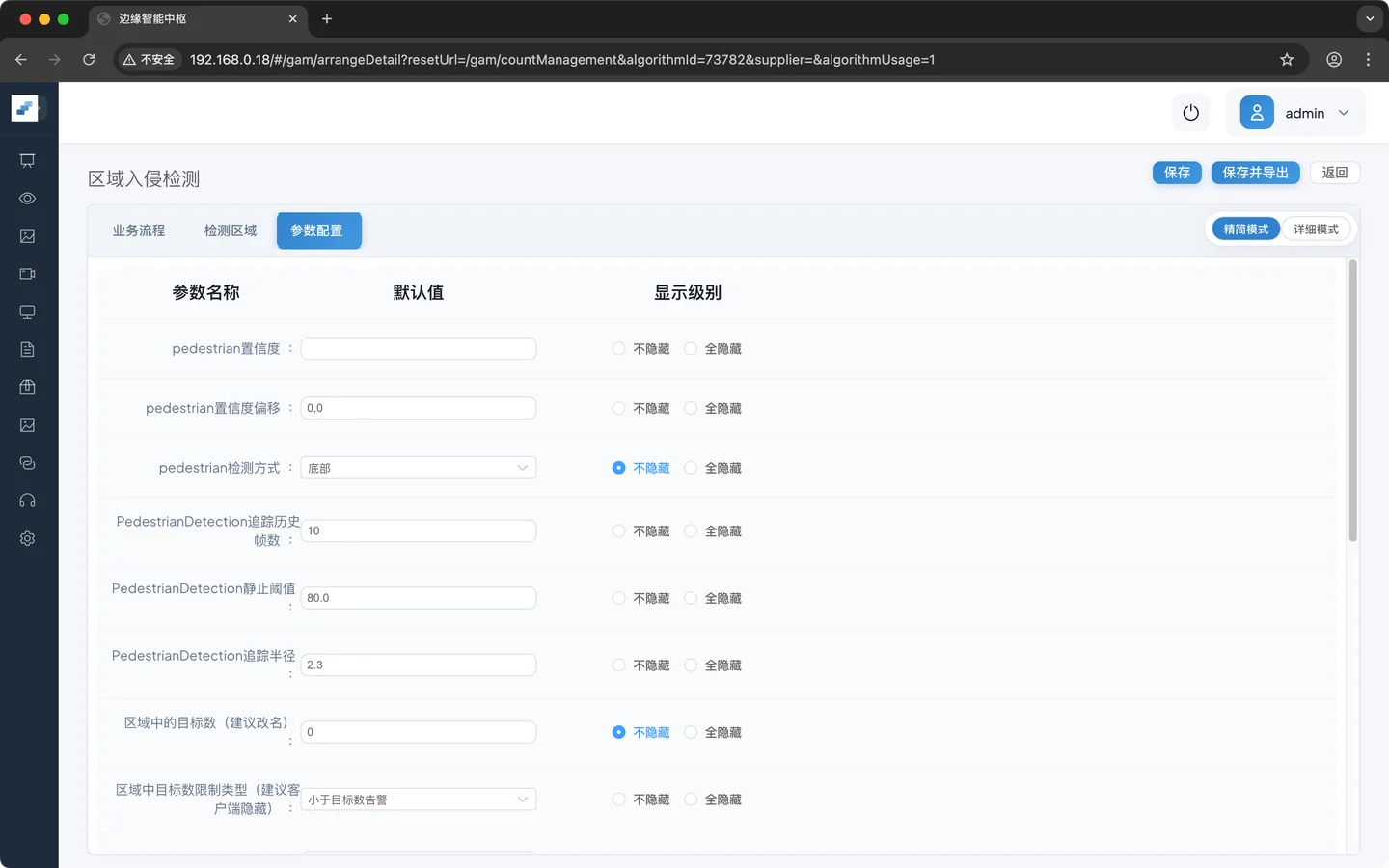
目标检测节点
| 参数 | 建议值 | 备注 |
|---|---|---|
| 置信度阈值 | 0.5 | 置信度可以上下浮动的数值 |
| 置信度偏移 | 0 | 指定检测框的某一点参与区域入侵检测,行人检测通常以脚进入检测框为入侵,所以配置底部。也可以配置中心点,顶部等 |
| 检测方式 | 底部 |
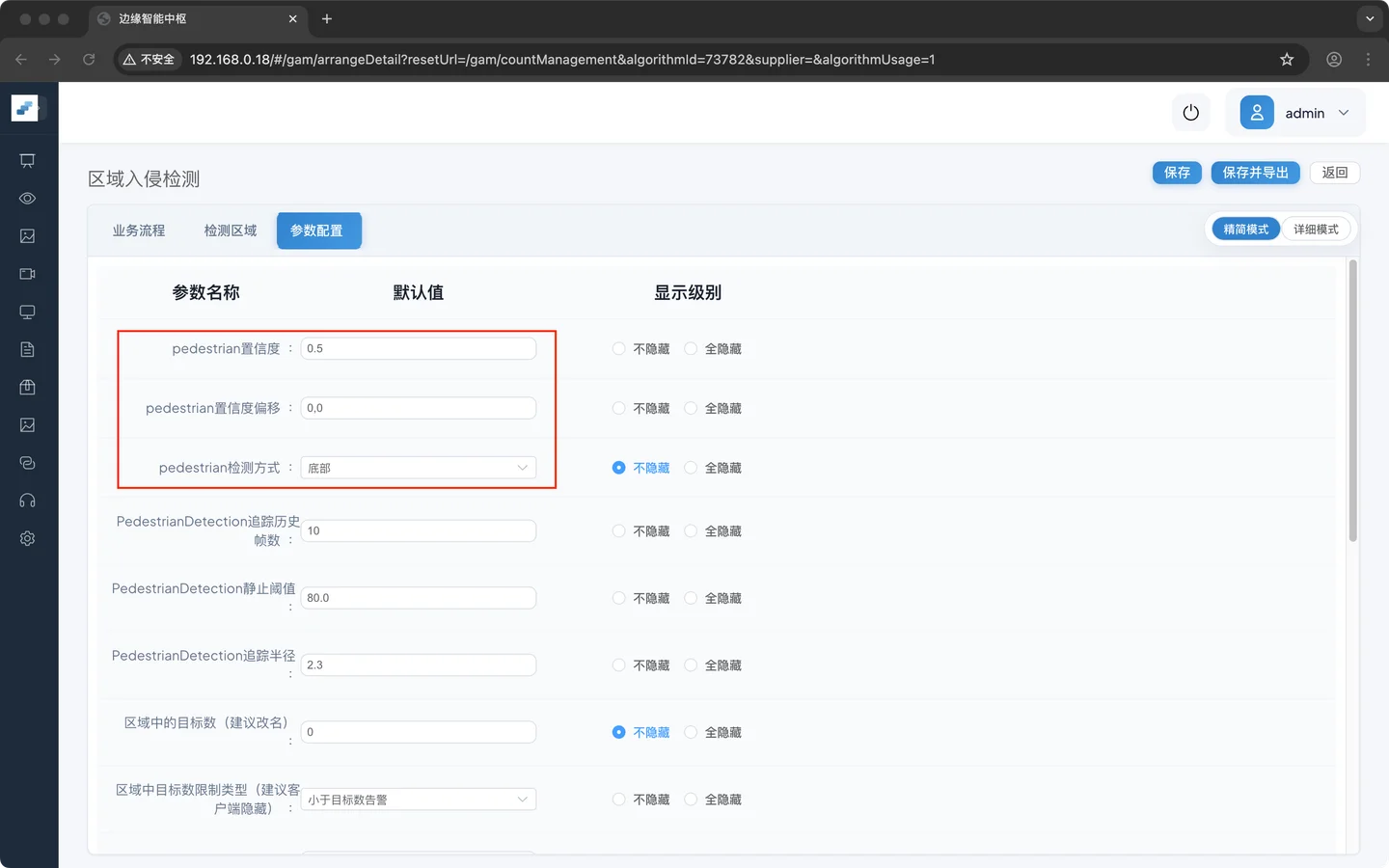
追踪算法
| 参数 | 建议值 | 备注 |
|---|---|---|
| 追踪历史帧数 | 10 | 追踪超过N帧才算追踪成功 |
| 静止阈值 | 80 | 追踪器的追踪阈值大于80% ,系统判断目标静止 |
| 追踪半径 | 2.3 | 追踪2.3m以内的目标,上下帧超过2.3则认为目标丢失 |
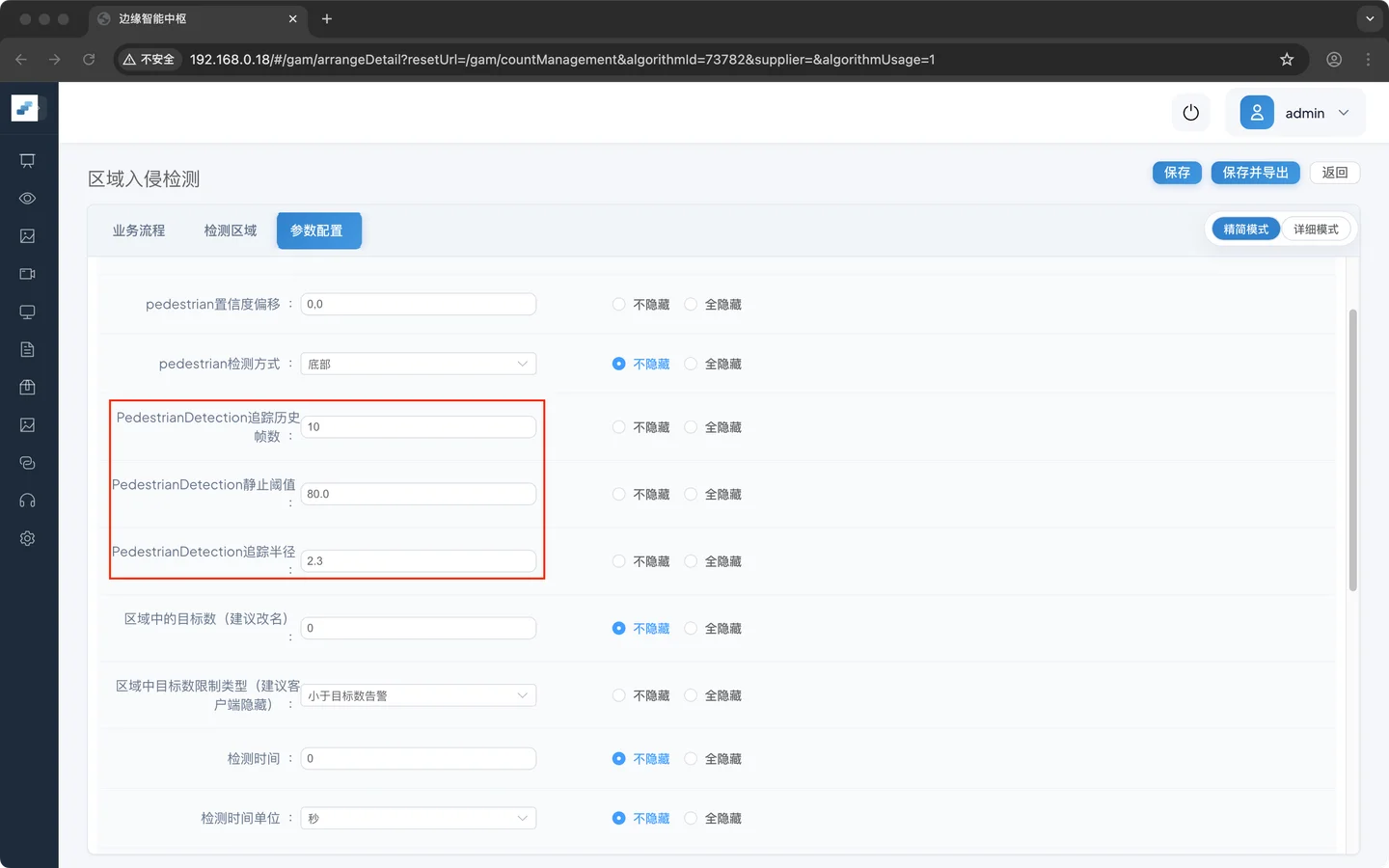
区域告警判断
| 参数 | 建议值 | 备注 |
|---|---|---|
| 区域中的目标数 | 0 | 大于或小于该目标数触发告警事件。(大于或小于根据目标数限制类型的条件决定) |
| 区域中目标数限制类型 | 大于目标数告警 | 告警条件,用于判断目标出现、聚集等 |
| 检测时间 | ||
| 检测时间单位 |
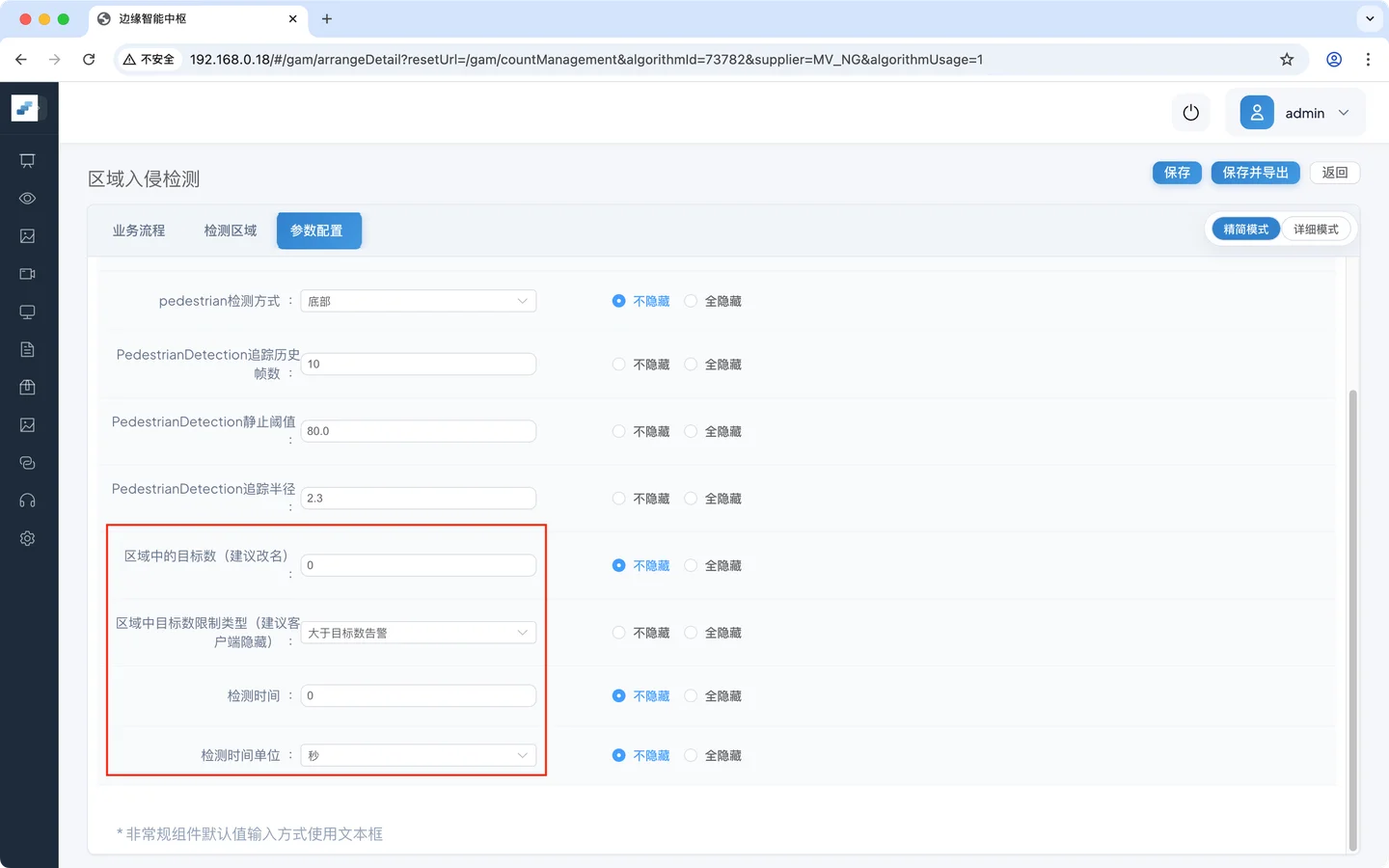
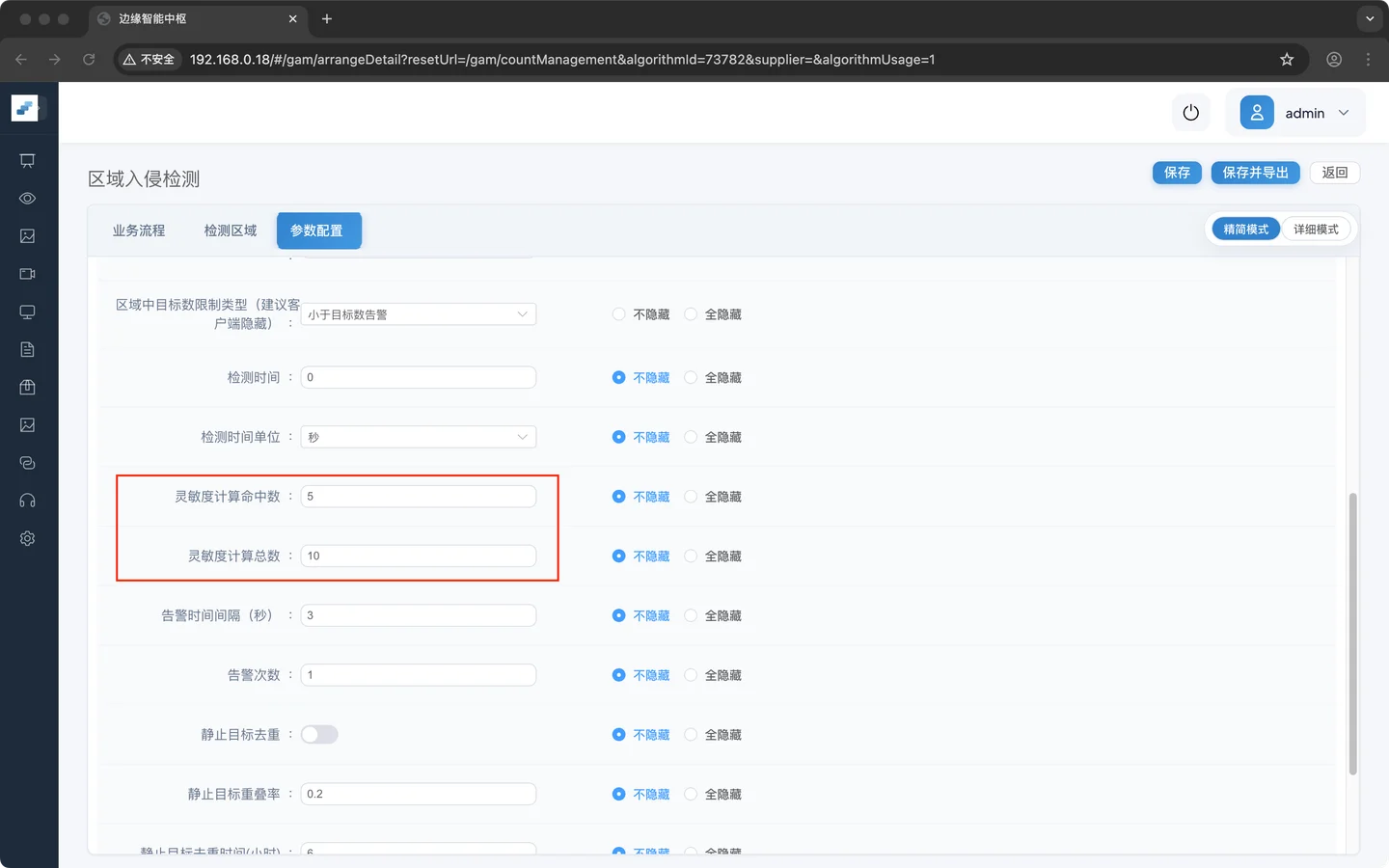
灵敏度计算节点
| 参数 | 建议值 | 备注 |
|---|---|---|
| 灵敏度计算命中数 | 3 | 连续命中 3 帧后触发 |
| 灵敏度计算总数 | 10 | 在 10 帧窗口内累计判断 |
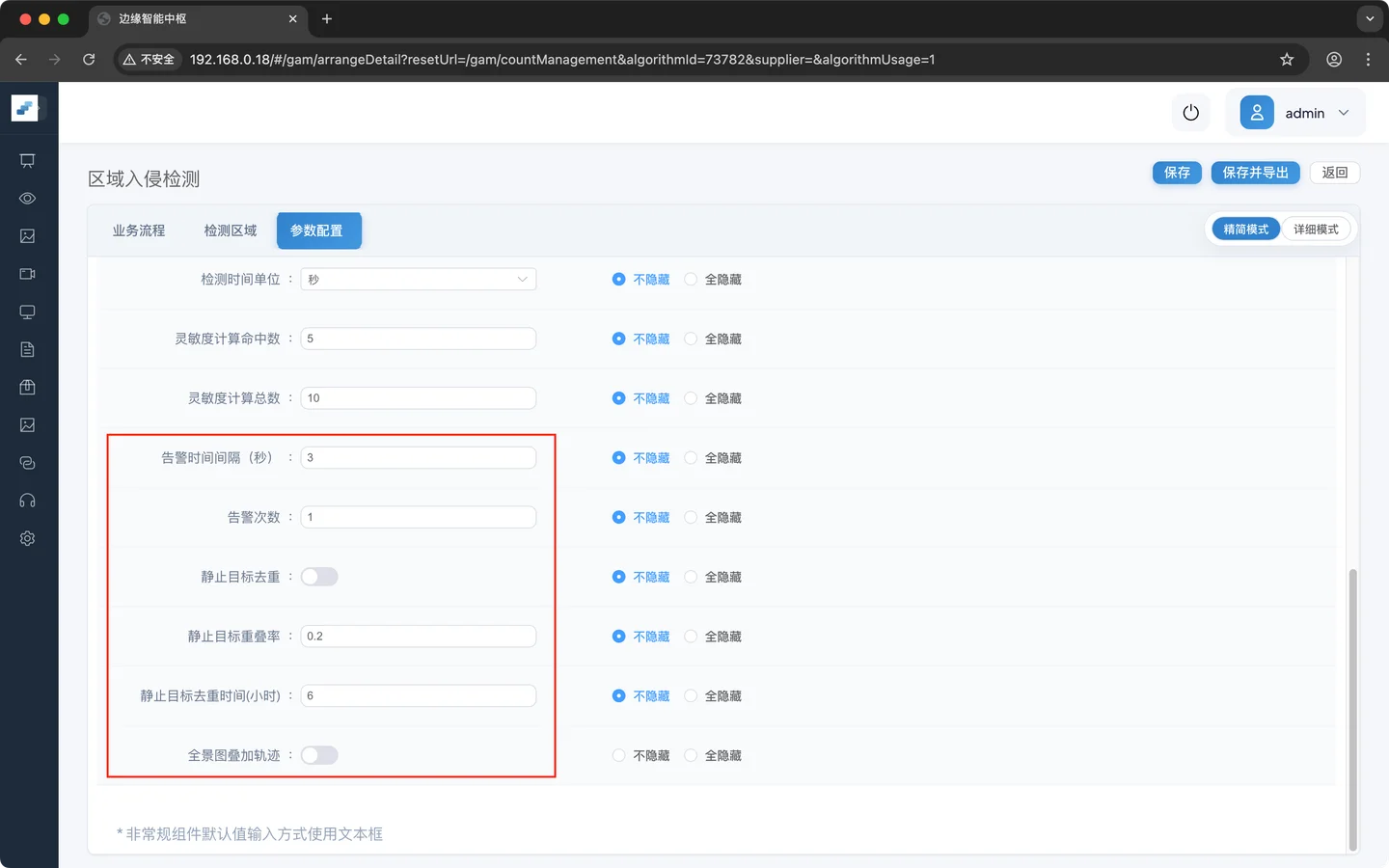
事件上报节点
| 参数 | 建议值 | 备注 |
|---|---|---|
| 告警时间间隔 | 3 | 告警之后再次告警的时间间隔 |
| 告警次数 | 1 | 检测到同一目标的重复告警次数,防止告警记录过多 |
| 静止目标去重 | 开启 | 静止的目标会大量重复告警,开启静止目标去重让静止的目标不会重复告警 |
| 静止目标重叠率 | 0.2 | 静止目标的判断标准,重叠超过阈值判断为静止 |
| 静止目标去重时间 | 6 | 静止目标去重的最大时间限制 |
| 全景图叠加轨迹 | 不开启 | 可视化叠加添加轨迹 |
3.5 分配到视频通道并测试
- 创建视频通道
点击 视频接入 进入通道页面
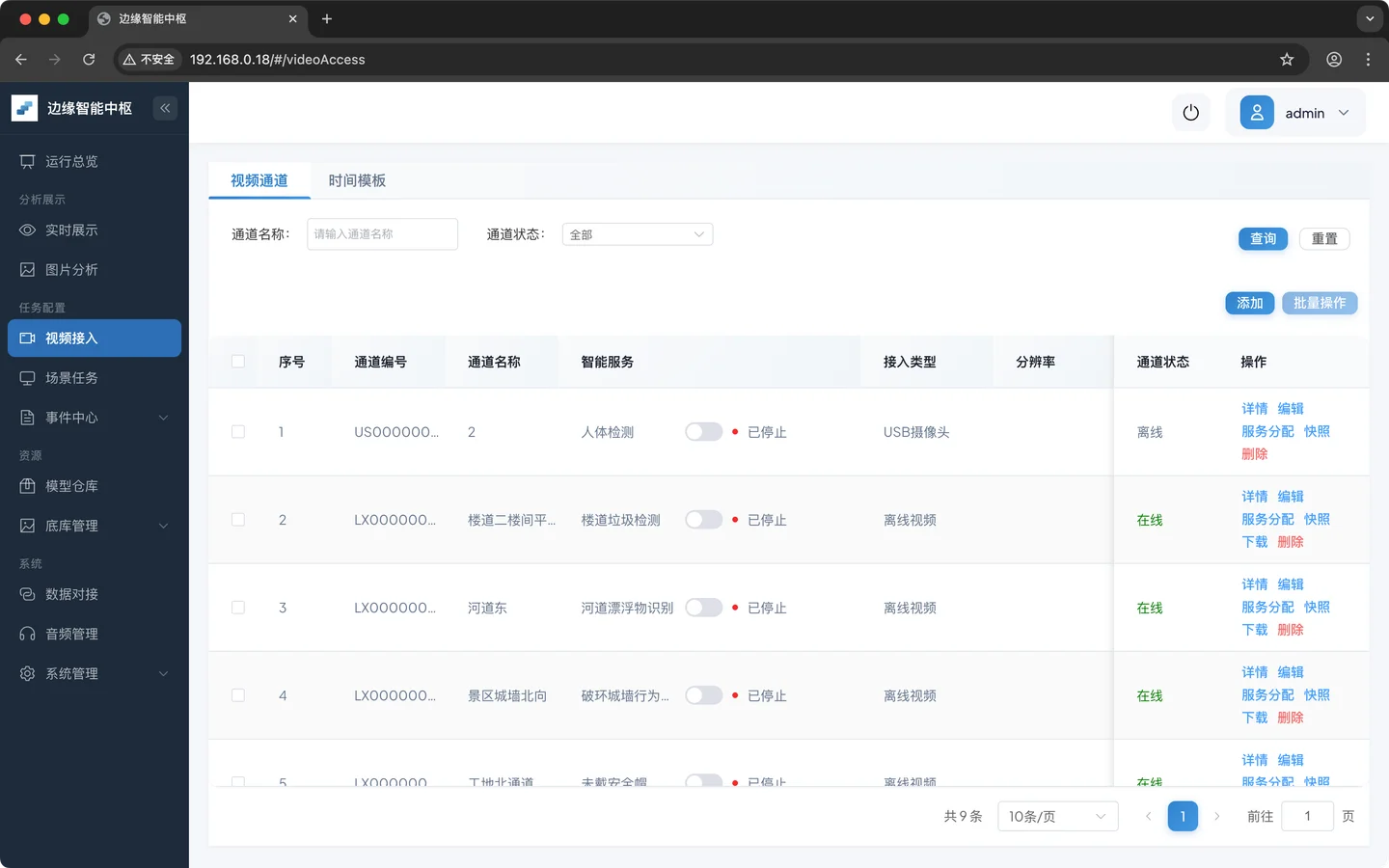
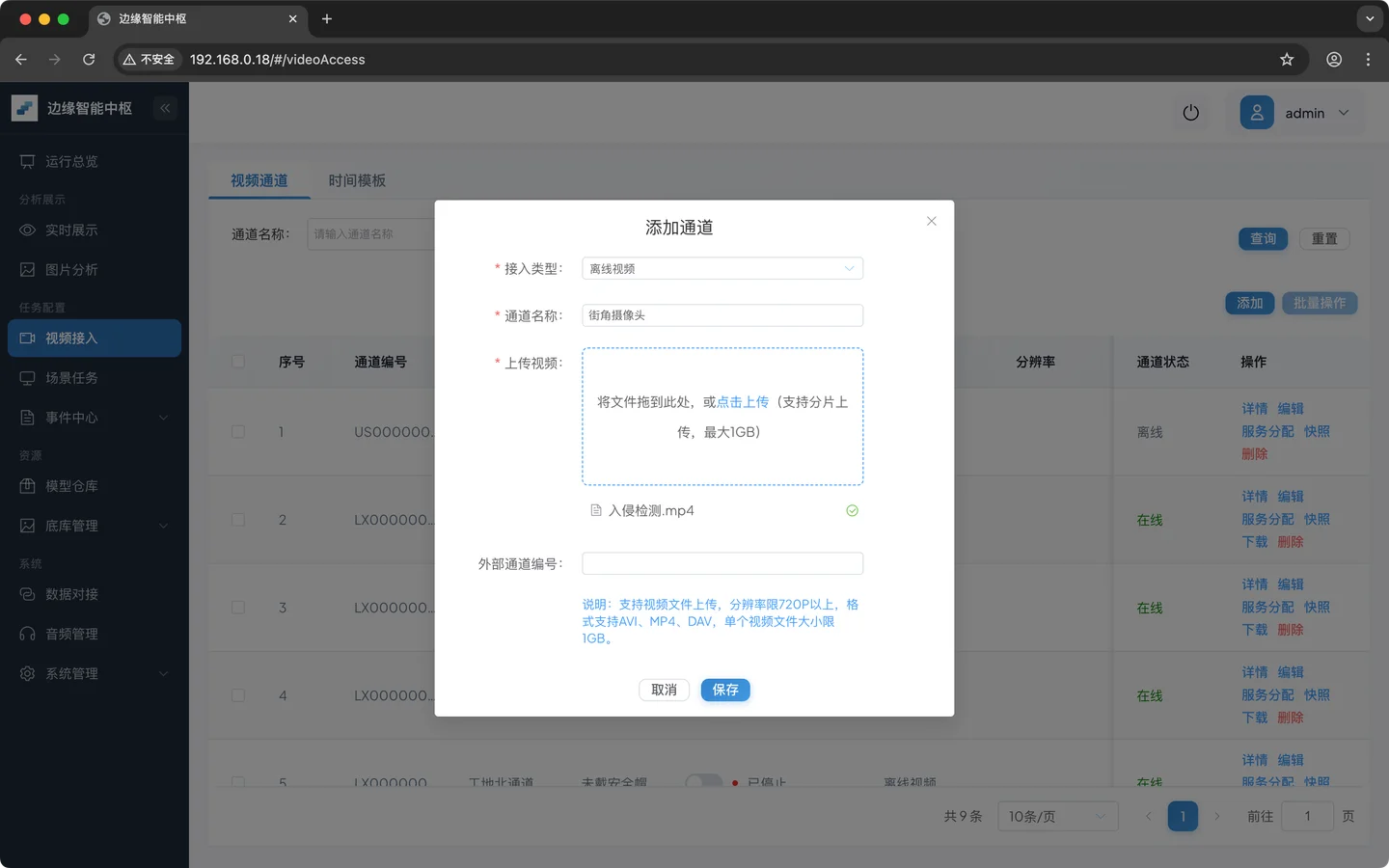
新建通道并上传视频
- 进入 服务分配
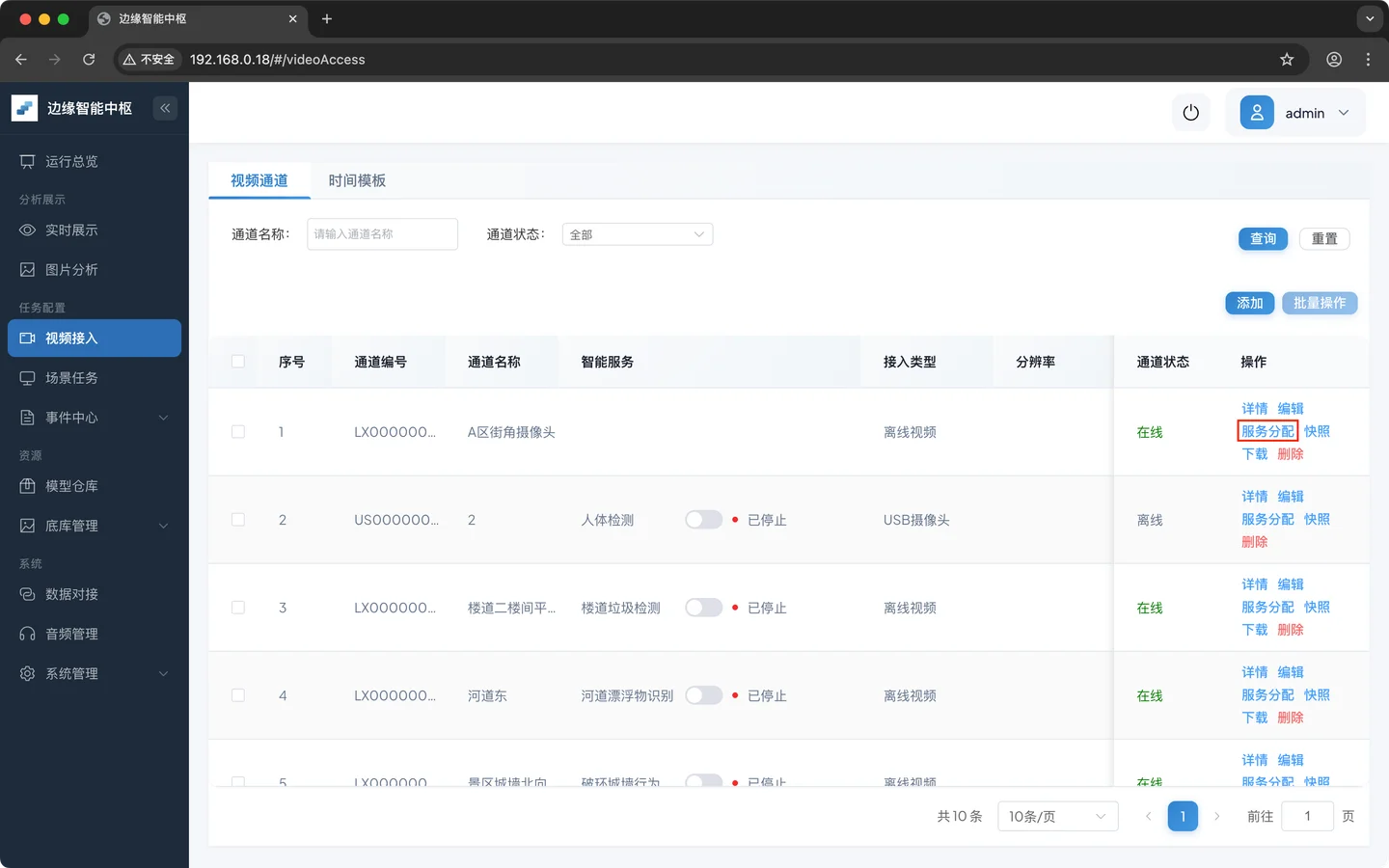
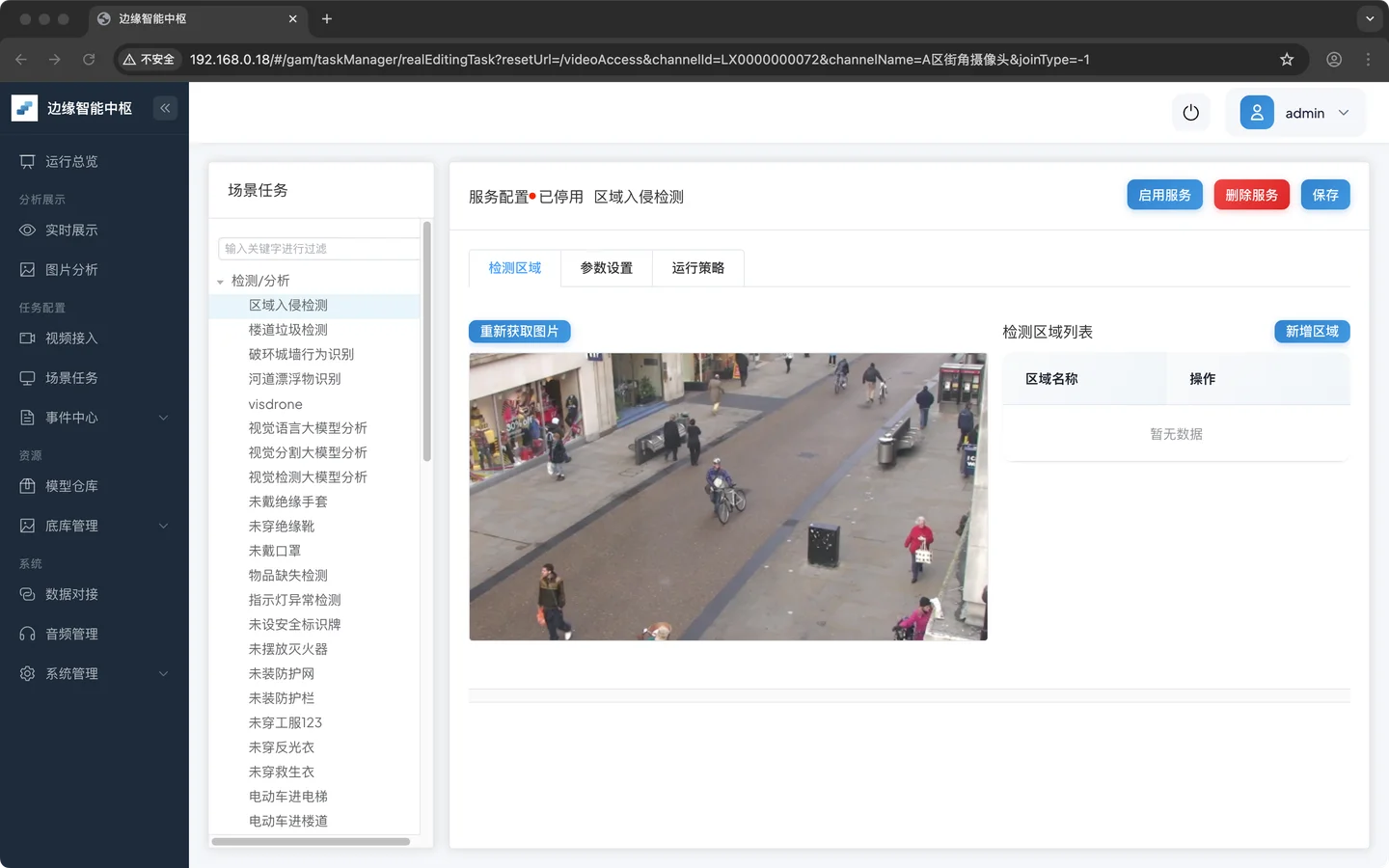
- 选择刚刚创建的 **区域入侵检测 **任务
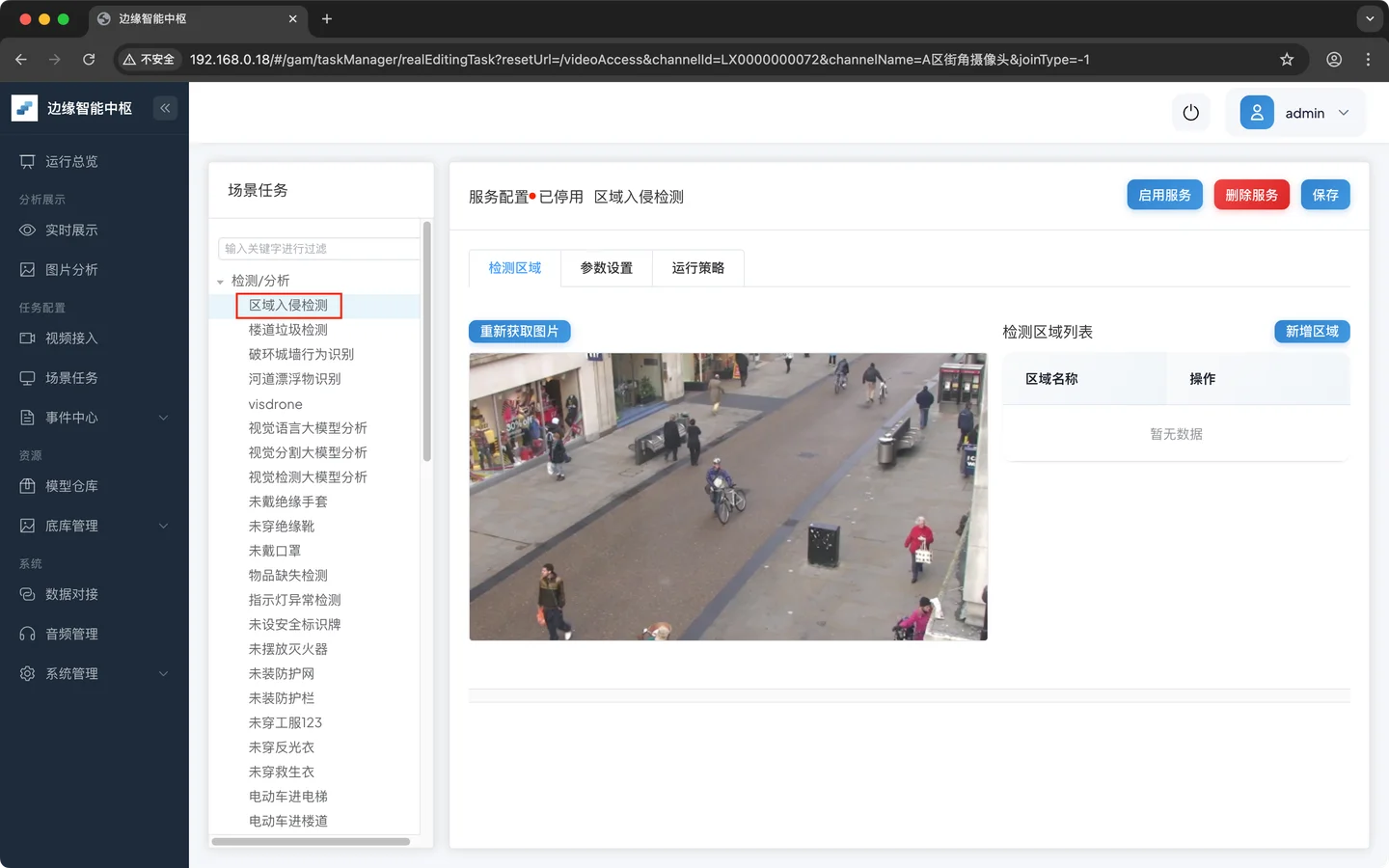
- 绘制检测区域
点击 新增区域
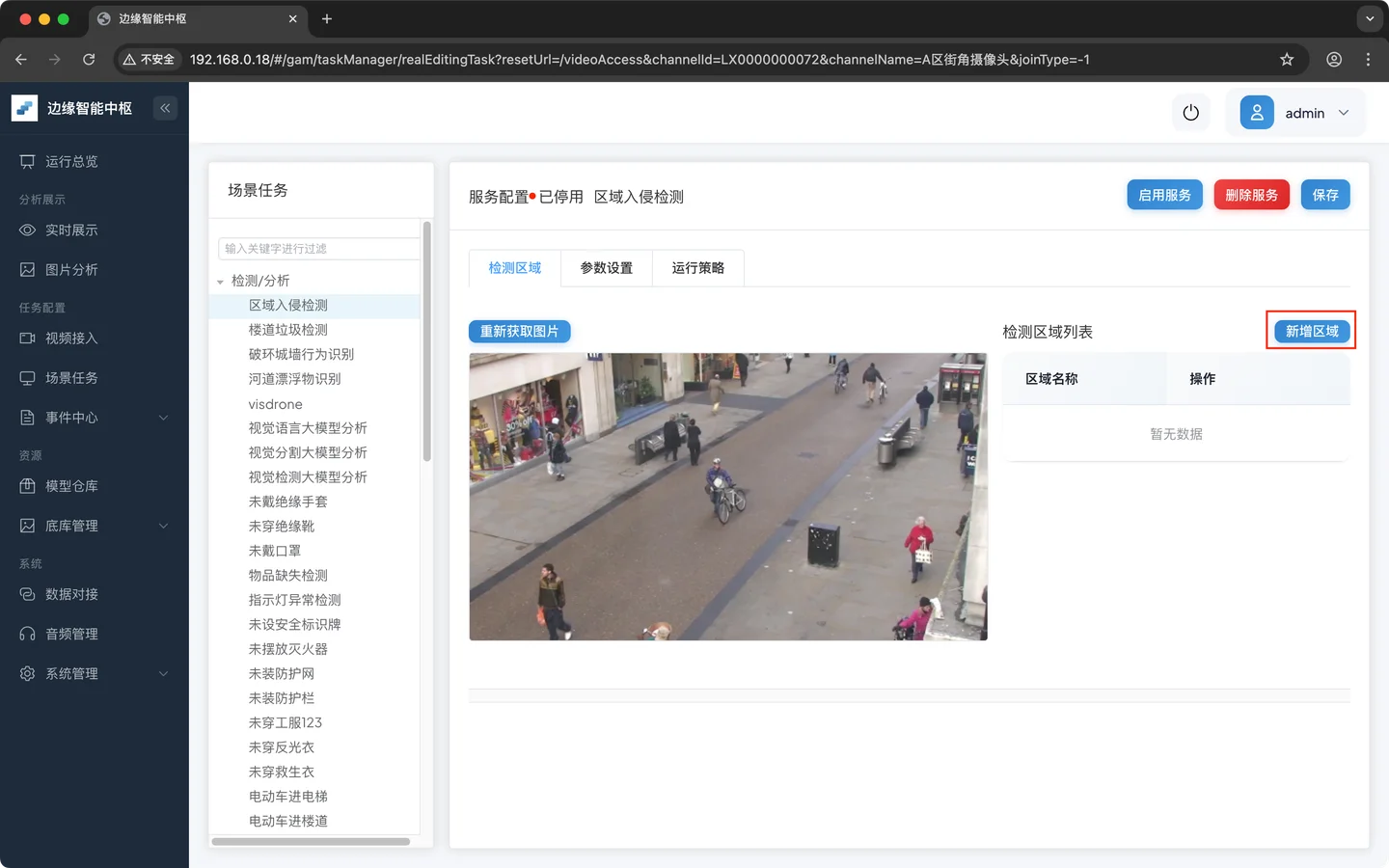
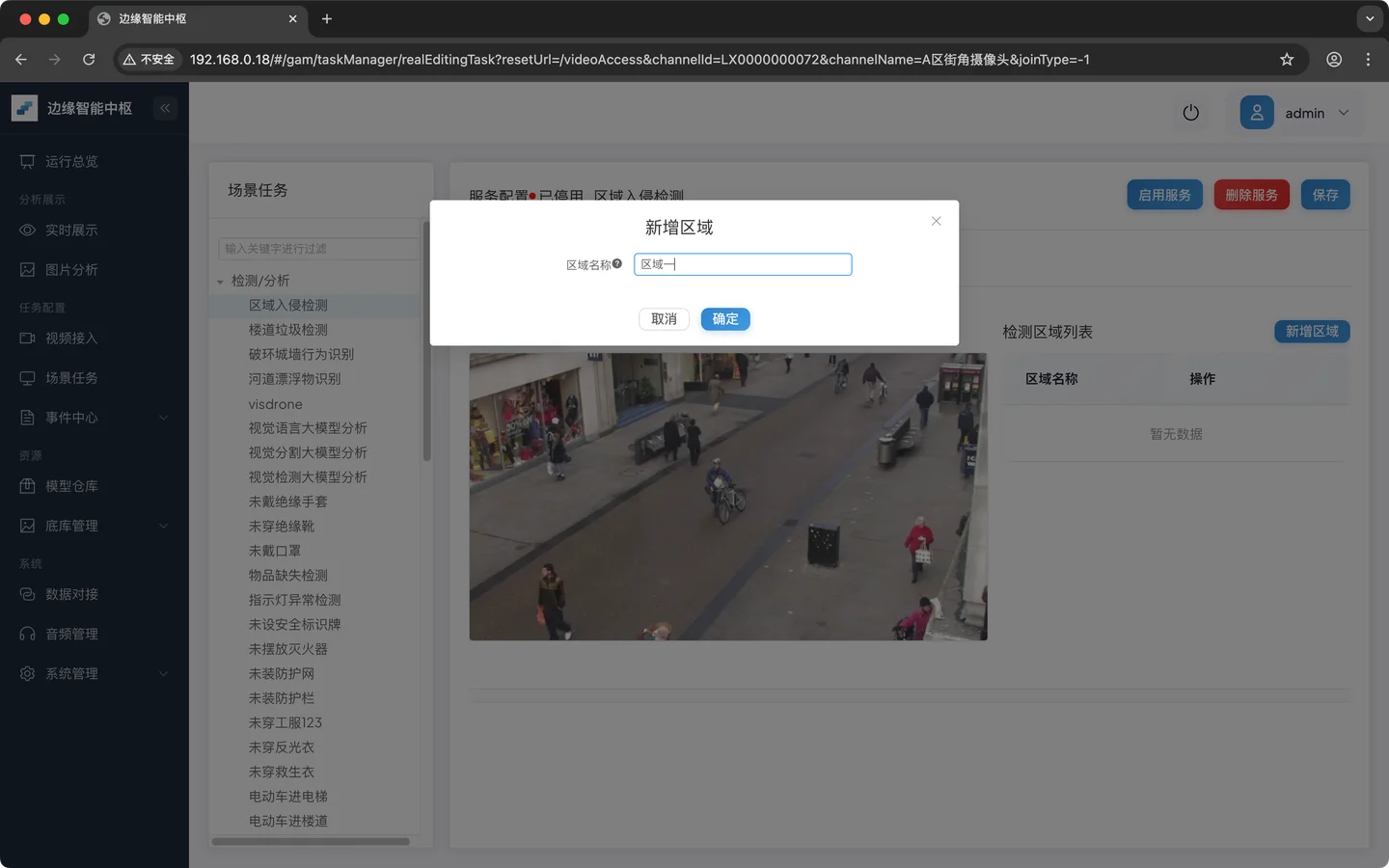
调整区域的位置
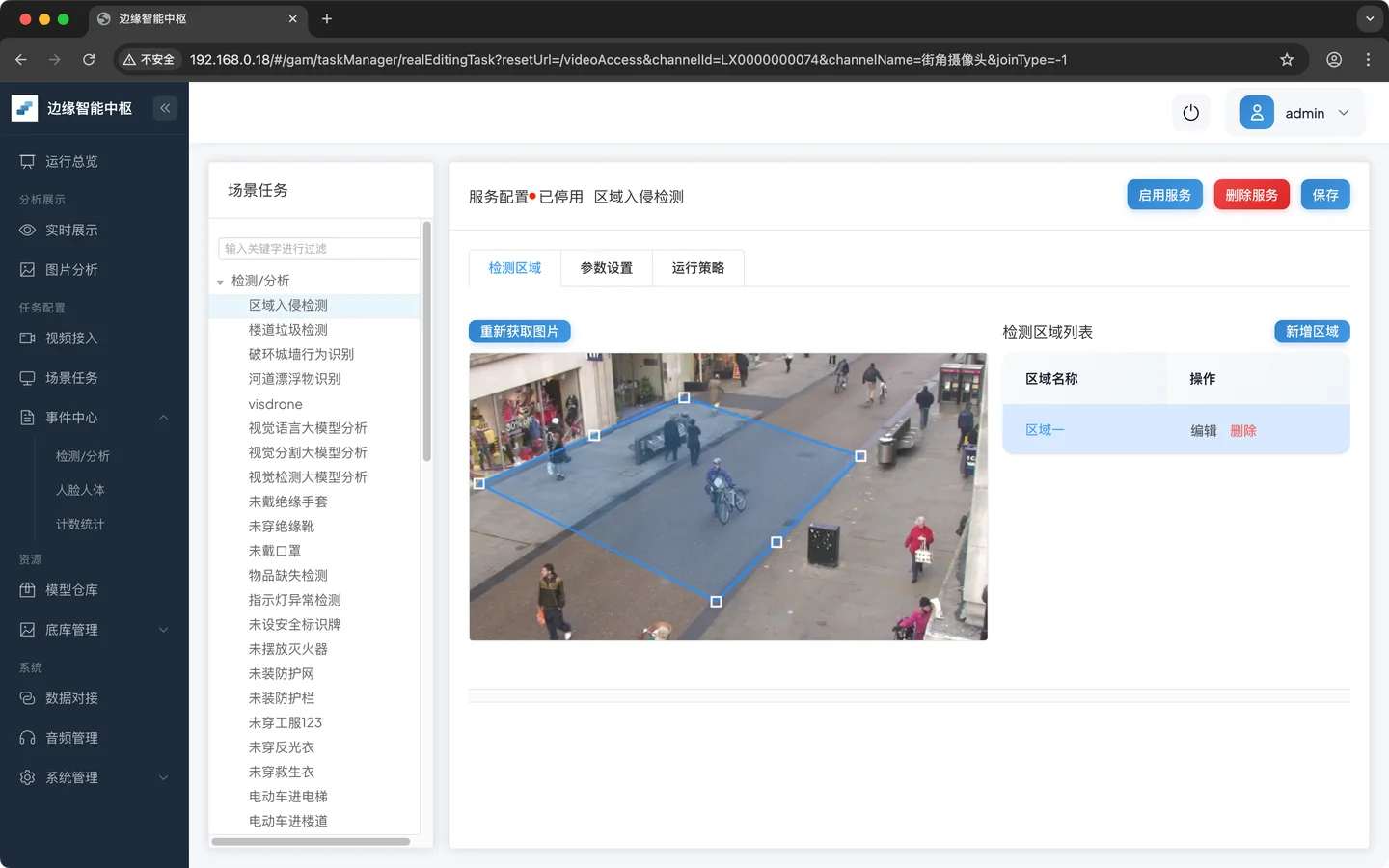
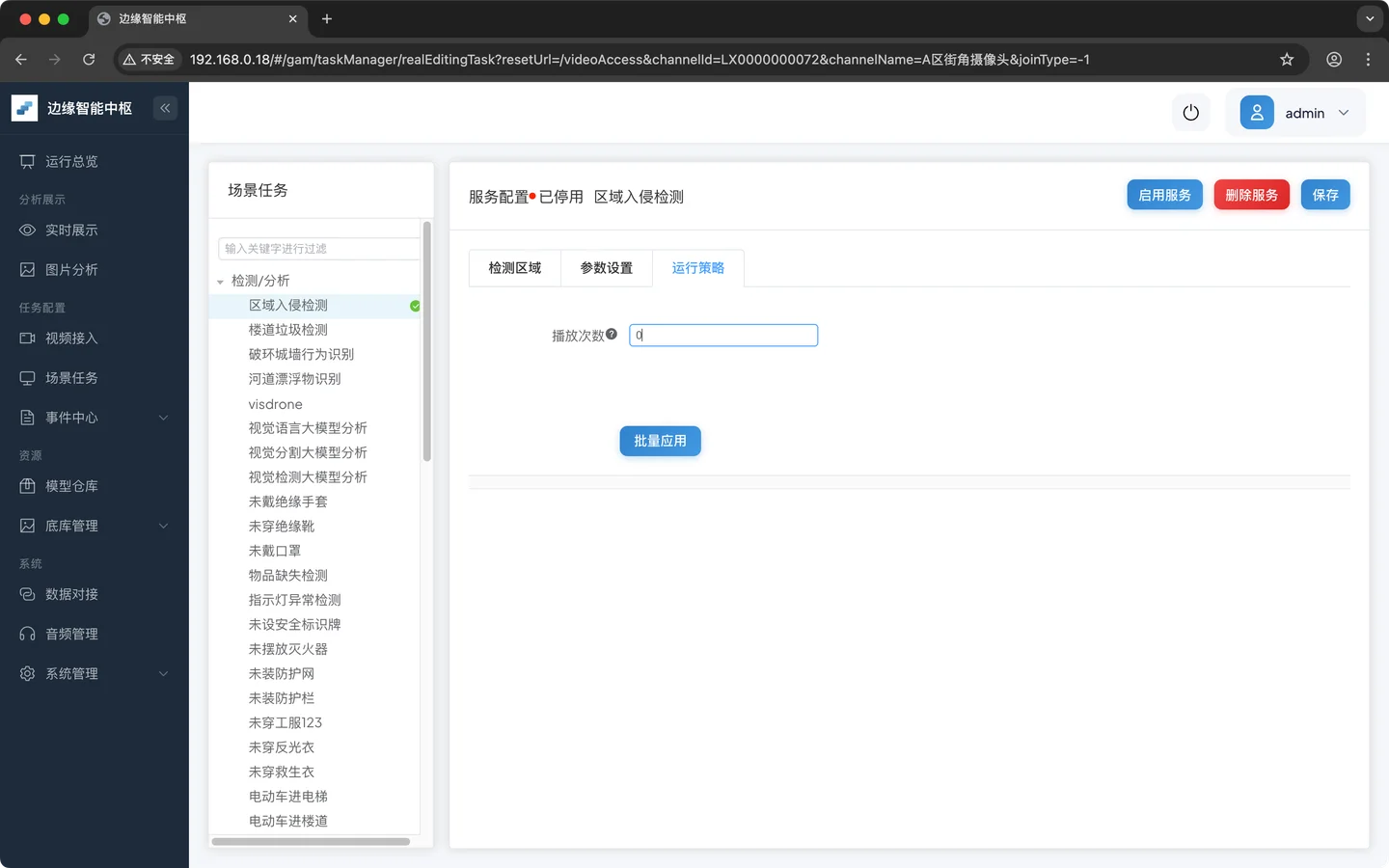
- 配置运行策略
播放次数修改成0,表示循环播放
- 保存并启动服务
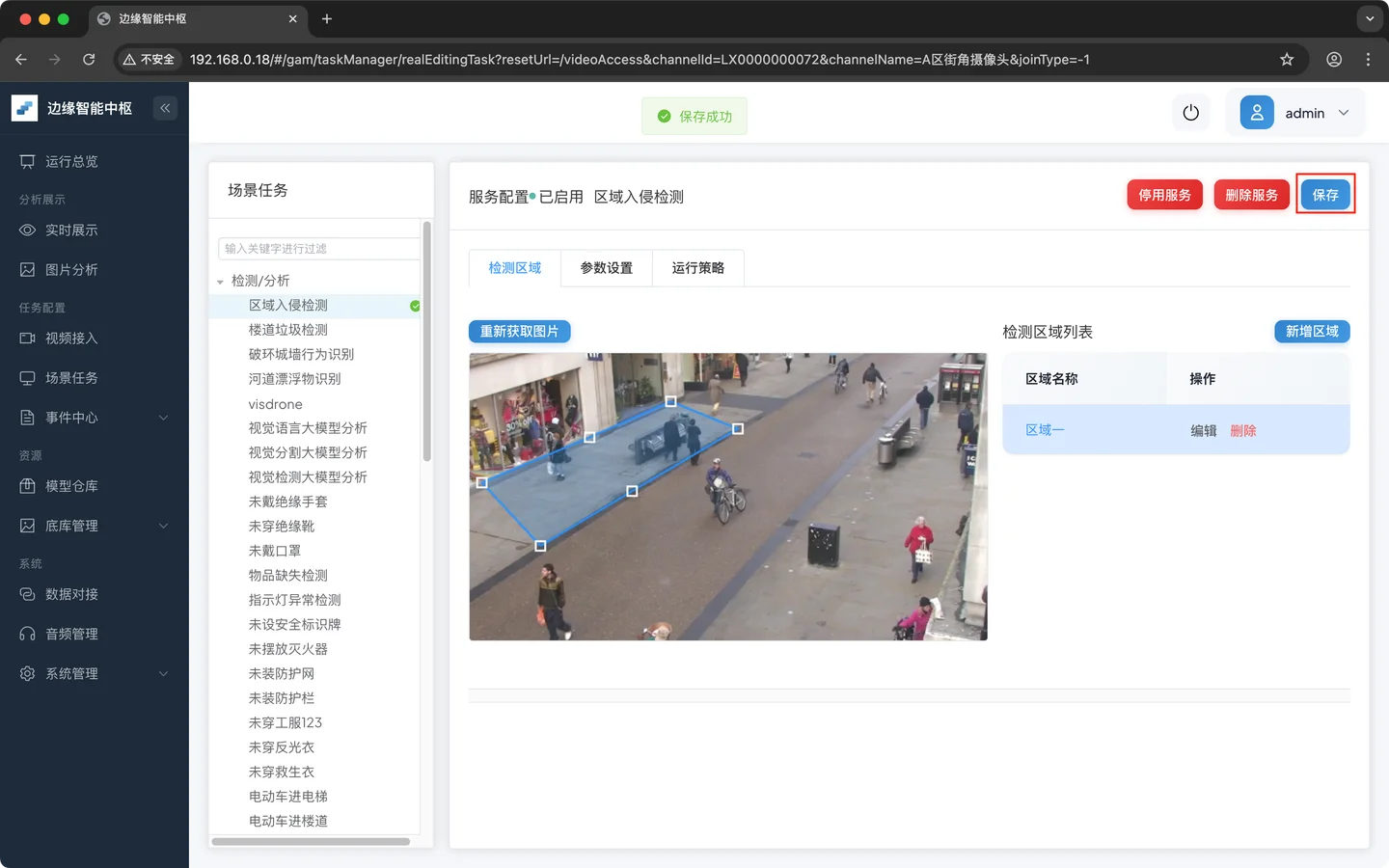
3.6 验证效果
进入 实时展示 和 告警记录 检查结果。
- 点击 实时展示,进入展示页面
- 选择 A区街角摄像头
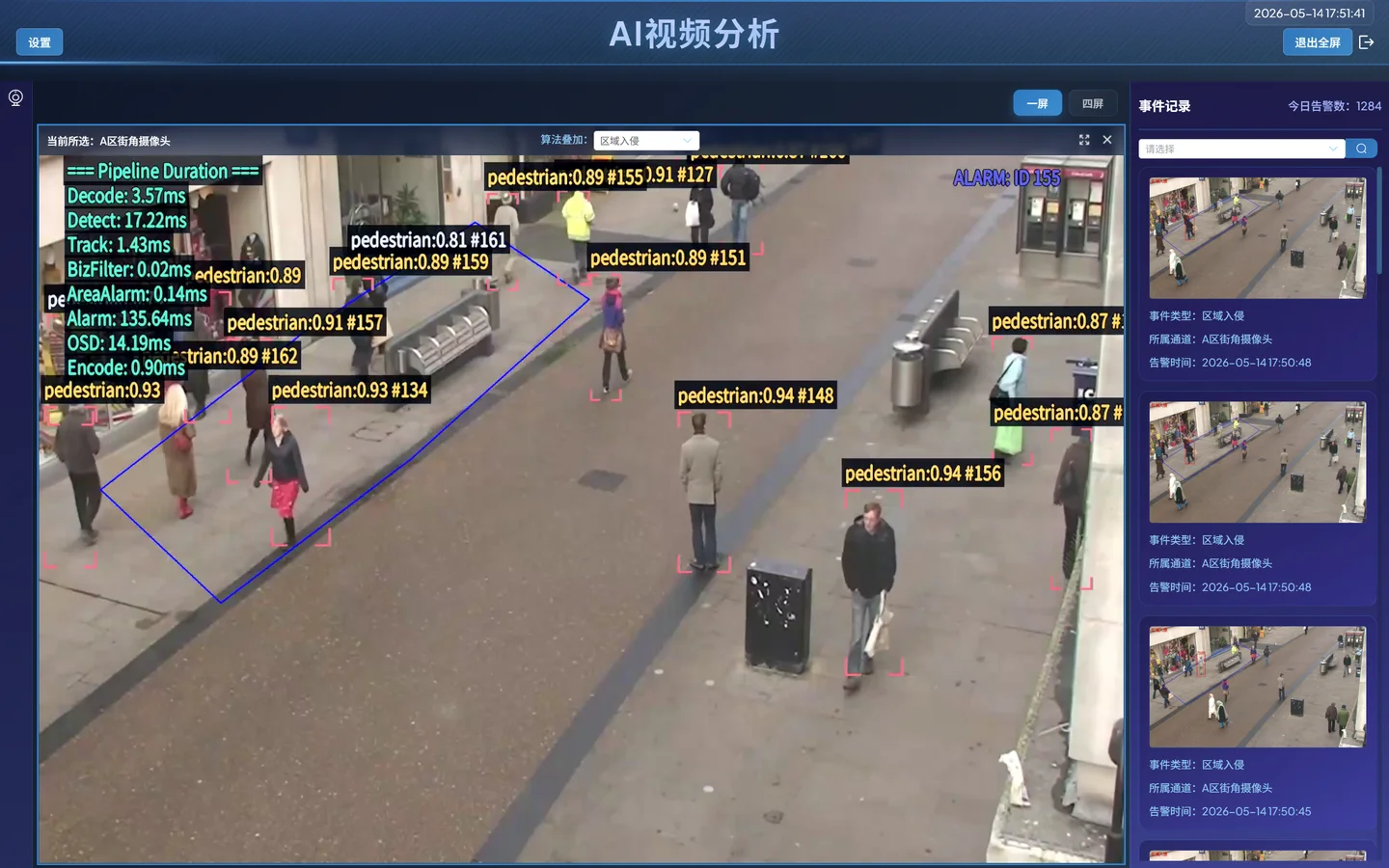
- 可视化叠加
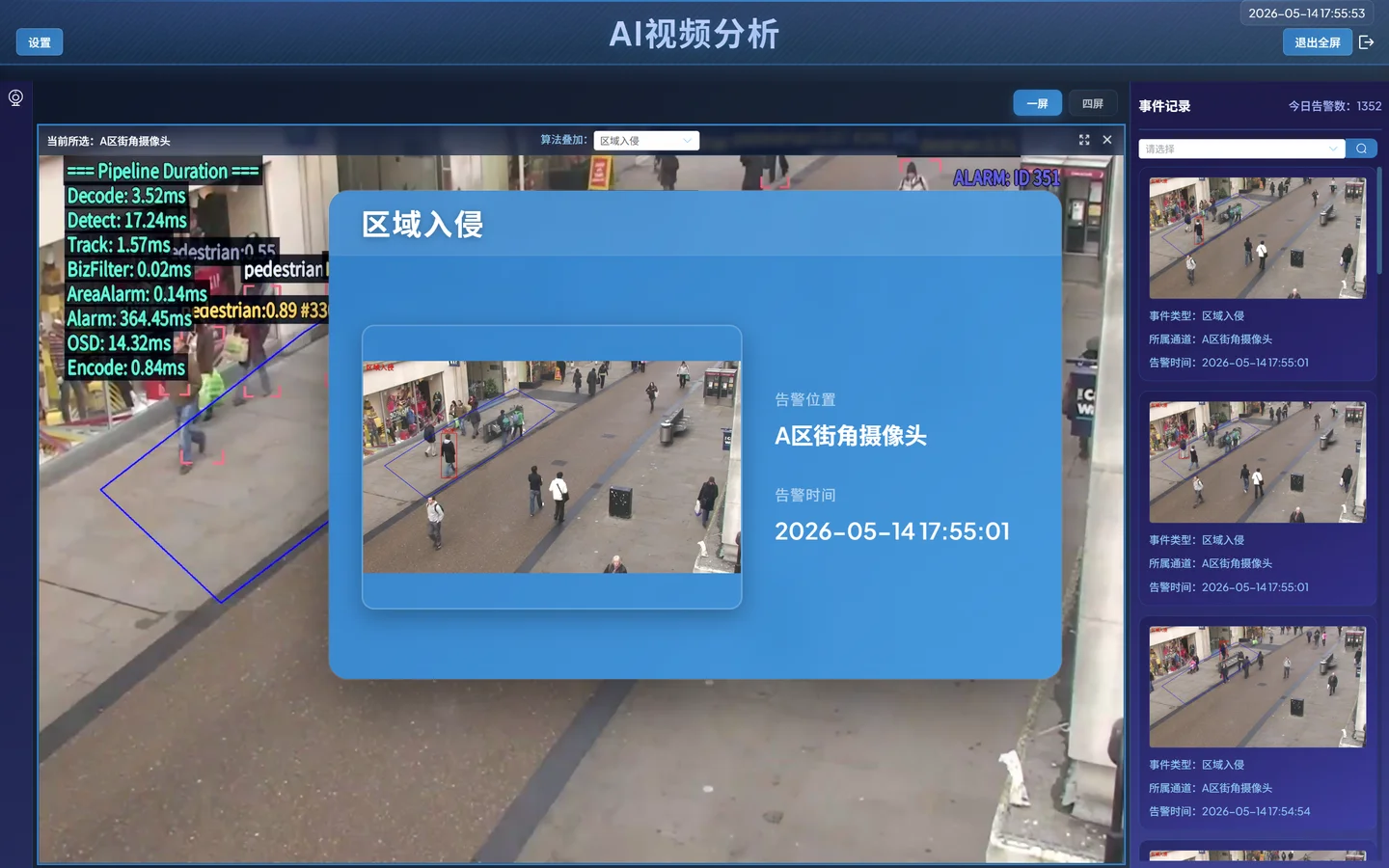
- 弹出告警记录
结果分析
- 人员进入指定区域后,实时画面出现检测框和标签
- 连续命中后触发告警,而不是单帧即报警
- 告警记录中能看到对应事件
- 告警记录
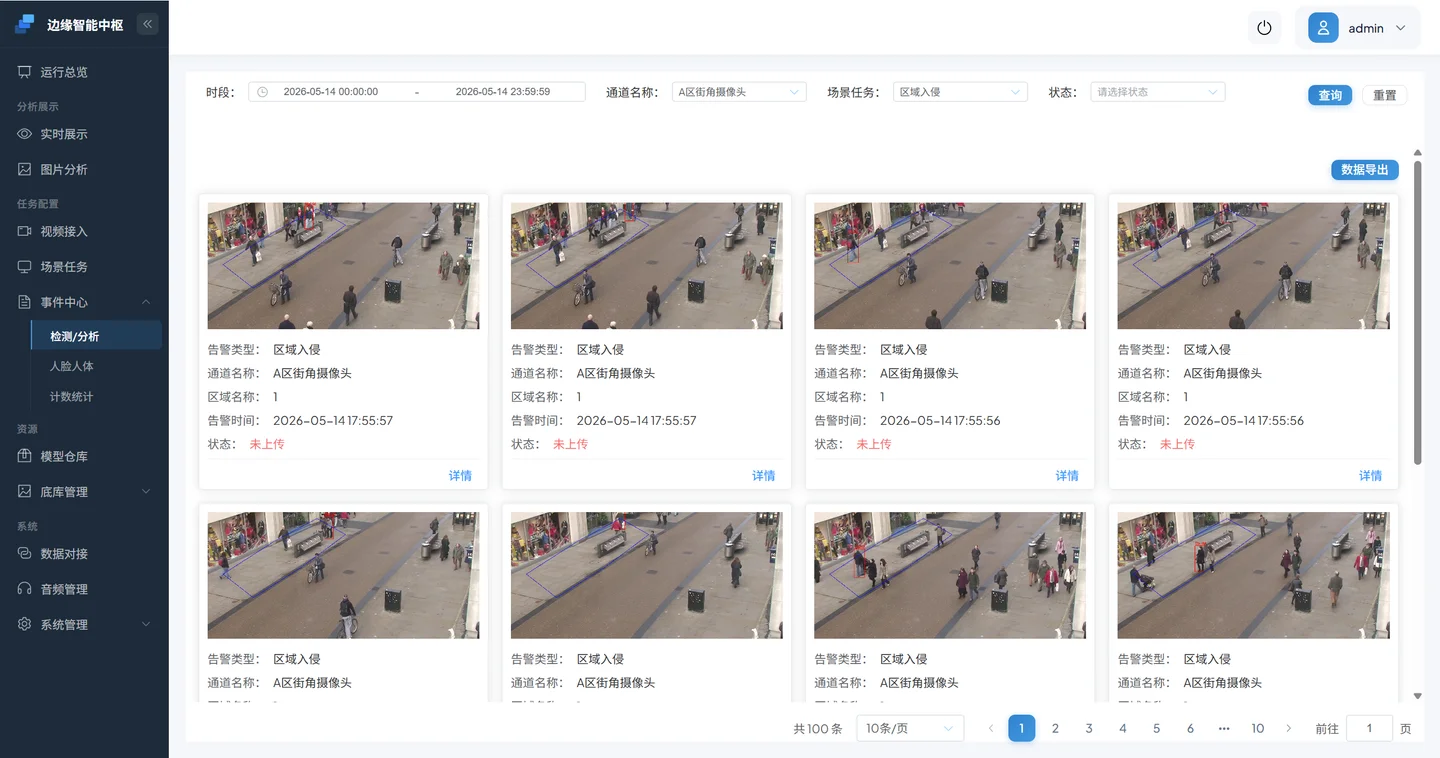
到这里,您已经完成了第一次“从零创建 场景任务”。
附录
A. 节点速查表
WARNING
待补充
B. 节点参数速查表
| 节点类型 | 常用参数 | 默认/建议值 | 备注 |
|---|---|---|---|
| 视频解码 | 解码方式 | 硬解码 | 通常无需修改 |
| 目标检测 | 模型 / 置信度阈值 | 0.5 | 低于阈值的结果将被丢弃 |
| 目标追踪 | 最大丢失帧数 | 30 | 丢失多久后释放 ID |
| 目标尺寸过滤 | 最小宽度 / 最小高度 | 0 | 0 表示不过滤 |
| 区域判定 | 判定方式 | 底边中心点 | 判断目标是否在区域内 |
| 灵敏度计算 | 命中阈值 / 窗口大小 | 3/10 | 多帧累计后触发 |
| 事件上报 | 告警类型 / 告警间隔 | 60 秒 | 同一目标重复上报间隔 |
C. 常见编排错误排障
| 问题 | 可能原因 | 解决方法 |
|---|---|---|
| 保存后服务无法启动 | 节点未正确连线 | 检查节点是否全部连通 |
| 实时画面无检测框 | 缺少 视频可视化 叠加节点 | 在末端添加 视频可视化 叠加 |
| 有框但无告警 | 缺少事件上报或灵敏度未命中 | 检查上报节点和阈值 |
| 告警过多 | 缺少灵敏度计算或阈值太低 | 提高灵敏度门槛 |
| 误报较多 | 未使用尺寸过滤或区域判定过宽 | 收紧过滤和区域范围 |
D. 常见 场景任务模板
检测型 场景任务
视频解码 → 目标检测 → 目标追踪 → 事件上报 → 视频可视化叠加适用:纯目标检测、异物检测、车辆检测等
检测 + 规则型 场景任务
视频解码 → 目标检测 → 目标追踪 → 区域判定/越线判定 → 灵敏度计算 → 事件上报 → 视频可视化叠加适用:区域入侵、周界检测、客流统计等
检测 + 分类型 场景任务
视频解码 → 目标检测 → 目标追踪 → 类别过滤 → 目标分类 → 灵敏度计算 → 事件上报 → 视频可视化叠加适用:安全帽、工服、吸烟、玩手机等
下一步
如果您已经掌握本篇教程内容,下一步建议进入:
- CosmoEdge 第三方模型移植
该将解决另一个关键问题: 如何把第三方模型移植到设备,并把它接入您自己创建的 场景任务。